
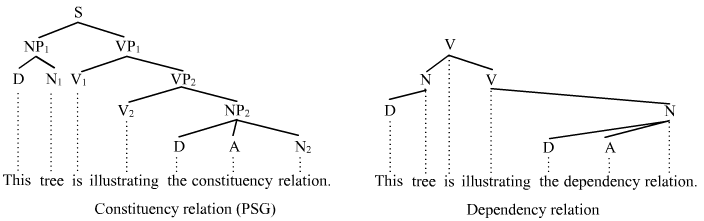
チョムスキー言語学と自然言語処理
Introductio to the Chomsky's Syntactic Theory for dummy
私は「赤いリンゴ5個」と書かれているメモを渡す—— Ludwig Josef Johann Wittgenstein
★今日の応用チョムスキー理論は、自然言語処理における「大規模言語モデル
(LLM)」に反映されている。大規模言語モデル(LLM)とは、以下のようなものである(灰色のセルの中は完全引用=コピペである)
| 大規模言語モデル(Large
Language Models、LLM)とは、非常に巨大なデータセットとディー
プラーニング技術を用いて構築された言語モデルです。ここでいう「大規模」とは、従来の自然言語モデルと比べ、後述する3つの要素「計算
量」「データ量」「パラメータ数」を大幅に増やして構築されていることに由来します。大規模言語モデルは、人間に近い流暢な会話が可能であり、自然言語を
用いたさまざまな処理を高精度で行えることから、世界中で注目を集めています。 |
|
| 言語モデルとは 「言語モデル」とは、文章の並び方に確率を割り当てる確率モデルです。例えば、ある画像からそれが猫かどうかを当てる「予測モデル」を考えると、猫に近い 画像は猫であるという確率を高く割り当て、犬に近い画像は猫であるという確率を低く割り当てます。同様に、「言語モデル」の場合、より自然な文章の並びに 対して高い確率を割り当て、文章として成立しない並びには低い確率を割り当てます。 こうした「言語モデル」自体には古い歴史がありますが、2018年に「BERT」というディープラーニング技術を用いた新しいアーキテクチャによる言語モ デルがGoogleより発表されました。「BERT」は、文章全体の意味を捉えられるという点で従来技術より優れ、かつ規模を大きくすることで精度を向上 させやすいという特長があります。Googleの発表後、この「BERT」を応用した言語モデルが多く生まれ、実用範囲が急速に拡大しています。 |
|
| 大規模言語モデルは「計算量」「データ量」「モデルパラメータ数」の3
つが巨大化 「大規模言語モデル」は、言語モデルのうち「計算量」「データ量」「モデルパラメータ数」の3要素を大規模化したものを指します。「計算量」とはコン ピュータが処理する仕事量のことで、「データ量」とはコンピュータに入力した文章データの情報量です。また「モデルパラメータ数」とは、ディープラーニン グ技術に特有のパラメータ(確率計算を行うための係数の集合体)の豊富さを指します。大規模言語モデルは、この3つを巨大化させることで急速に進化しまし た。 この3つの巨大化については、2020年にOpenAIが発表した「Scaling Laws for Neural Language Models*1」という論文で説明されています。この論文では、自然言語モデルの性能と、この3つの要素「計算量」「データ量」「モデルパラメータ数」 との間に、「Scaling Law(べき乗則)」が成立すると提唱されました。OpenAIは、この論文に裏打ちされた形で、「計算量」「データ量」「モデルパラメータ数」の3つを 著しく巨大化することで、極めて精度の高い大規模言語モデルを生成することに成功しています。2022年11月に発表されたChatGPTも、「大規模言 語モデル」の一種であり、格段に優れた受け答えにより、自然言語での応答の質を大幅に高めています。 |
|
| 大規模言語モデルの活用分野 大規模言語モデルは、チャットボットや検索エンジン、翻訳、顧客の声分析、議事録生成、文章要約など、自然言語を用いる様々なタスクに応用できるのではな いかと期待されています。ChatGPTを開発したOpenAI社はMicrosoftの出資を受けていることから、Microsoftが提供するサーチ エンジン「Bing」にChatGPTの改良版が搭載されています。さらに自社開発するアプリケーションにも、順次大規模言語モデルの技術を搭載すること を発表しています。Microsoft以外にも、Googleが「Bard」、Metaが「LLaMA」を発表するなど、大手IT企業による開発競争が盛 んになっています。 |
|
| 大規模言語モデルの課題 圧倒的な性能を持つ大規模言語モデルであるが、現時点では課題もある。偽の情報を平然と出力する「hallucination(ハルシネーション、幻 覚)」と呼ばれる現象や、悪質なプロンプトを用いて、本来禁止されている機能を解除して不適切な回答を得ようとする「Prompt Injection(プロンプトインジェクション)」の問題などが指摘されている。性能向上と並行し、こういった課題を克服するための研究も進められて います。 |
|
| https://www.nri.com/jp/knowledge/glossary/lst/ta/llm |
★【古典】ノーム・チョムスキー『文法の構造』勇康雄訳、 pp.90-92, 研究社出版 , 1963年、より
ノーム・チョムスキー(Avram Noam Chomsky, 1928- )は、世界的に知られている言語学理論家そして平和理論家。
言語の構造についての2つのモデルがあった。1)言
語をひとつのマルコフ過程とみる考え方でこれは「伝達理論的モデル」という、
2)「構成素分析にもとづく句構造」のモデル(→句構造文法)である。
「文法は意味論とは別個の独立した研究と考える方が よい。特に文法性と いう考えは有意味性ということと同一視することはできない(またそれは 統計的近似値[order of approximation] という考えとは格別何らの関係 もない)。このように独立した形式的な研究をすすめる場合、文を左から右 へ作り出していく有限状態の[finite state] Markov process として言語を 考えるような単純な方法には賛成できないことがわかった。また句構造や 変形構造のようなかなり抽象的な言語レベルが自然言語の記述には必要で あることもわかった」(p.90)
「句構造による直接の記述は基本的な核文(すなわち 複雑な動詞句や名詞句を含まない単文、平叙文、能動文)だけに限定し、核文以外はすべてこ れらの基本文(もっと適確には、それらの基になっている連鎖)から変形に よって派生するようにすれば、英語の記述がきわめて簡潔になり、英語の 形態的構造に関して新たに重要な理解が得られる。逆に文法的文を他の文 法的文にかえる一連の変形を発見できれば、個々の文の構成分析がちがえ、 それらの変形を受けた場合の行動がどのようにかわるかを研究するこ とによって、それらの文の構成素構造を決定することができる」(p.90)
「したがって文法は三つの部分より成る構造をもつも のと考えられる。文 法には句構造を再構する一連のルールと、morphemes の連鎖をphonemes の連鎖にかえる一連のmorphophonemic のルールとがある。それらの二 つのルール群をつなぐものとして一連の変形ルールがあり、そのルールが 句構造を有する連鎖をmorphophonemic rules の適用される新しい連鎖 にかえる。句構造とmorphophonemic とのルールはtransformational rules とはちがって単純なものである。一つの連鎖に一つの変形を適用す るためには、その連鎖の派生の歴史についてある程度知らねばならない; しかし変形以外のルールを適用するためには、そのルールが適用される連 鎖の形を知るだけで十分である」(p.91)
「しかし意味の体系的考察は文法構造を決定する上に 役立たないように思われる。さ りとて、「辞書的意味」に対して「構造的意味」を考えることは賛成できな い。また言語の中に用いられている文法的装置に直接意味をつけられるほ ど用法が一貫しているかどうかは疑わしい。それでも、文法構造と意味と の潤には重要な関連がたくあんあることもきわめて当然である。言いかえ るなら、文法的装置はきわめて組織的に用いられていることがわかる。こ れらの相関関係を調べることは、文論と意味論の問題やその接点を考察す る一般言語理論の主題の一部となろう」(pp.91-92)
——ノーム・チョムスキー『文法の構造』勇康雄訳、 pp.90-92, 研究社出版 , 1963年
1. 序文
2. 文法の独立性
3. 単純な言語理論
4. 句構造(→「句構造文法(Phrase structure grammar)」)
5. 句構造的記述の限界
6. 言語理論の目標
7. 英語における変形の例
8. 言語理論のもつ説明力
9. 文論と意味論
チョムスキー言語理論のキーワードをあげてみる と……(ページ数は『増補版チョムスキー理論辞典』研究社、2016)
学部初学年むけの言語学入門だが、酒井優子教授の次 の授業「言語学が世界を一つにする」は、チョムスキー理論の入門としては非常に分かりやすくできている——酒井教授から引用承諾いただきました。
■
■チョムスキー理論の展開
1)拡大標準理論:初期〜1970年代
2)GB理論(一般化束縛Generalized Binding):1980年代
3)極小主義=ミニマリスト・プログラム:90年
代〜現在
●デカルト派言語学
デカルト言語学という言葉は、ノーム・チョムスキー による言語学の著書 『デカルト言語学』(1966年)の出版を機に作られたものである。1966年に出版されたノーム・チョムスキーの言語学に関する著書『デカルト言語学: 合理主義思想史の一断面』(日本経済新聞出版社)をきっかけに生まれた言葉。Cartesian」とは、17世紀の著名な哲学者であるルネ・デカルト (René Descartes)の形容詞である。しかし、チョムスキーはデカルトの著作にとどまることなく、合理主義思想に関心を持つ他の著者を調査している。特 に、普遍文法に関するチョムスキー自身のアイデアの一部を予見する書物である『ポルト・ロワイヤル文法』(1660年)を取り上げている(→「デカルト派言語学の検証」)。
●ノーム・チョムスキーの言語学(Linguistics of Noam Chomsky)
| What
started as purely linguistic research ... has led, through involvement
in political causes and an identification with an older philosophic
tradition, to no less than an attempt to formulate an overall theory of
man. The roots of this are manifest in the linguistic theory ... The
discovery of cognitive structures common to the human race but only to
humans (species specific), leads quite easily to thinking of
unalienable human attributes. —Edward Marcotte on the significance of Chomsky's linguistic theory[1] |
純粋に言語学的な研究として始まったものが......政
治的な大義への関与や古い哲学的伝統との同一化を経て、人間についての全体的な理論を打ち立てようとする試みにまで至った。そのルーツは言語理論にある。
人類に共通する、しかし人間にしかない(種特異的な)認知構造が発見されると、人間の譲ることのできない属性について考えるようになる。 -エドワード・マーコットは、チョムスキーの言語理論の意義について述べている[1]。 |
| The
basis of Noam Chomsky's linguistic theory lies in biolinguistics, the
linguistic school that holds that the principles underpinning the
structure of language are biologically preset in the human mind and
hence genetically inherited.[2] He argues that all humans share the
same underlying linguistic structure, irrespective of sociocultural
differences.[3] In adopting this position Chomsky rejects the radical
behaviorist psychology of B. F. Skinner, who viewed speech, thought,
and all behavior as a completely learned product of the interactions
between organisms and their environments. Accordingly, Chomsky argues
that language is a unique evolutionary development of the human species
and distinguished from modes of communication used by any other animal
species.[4][5] Chomsky's nativist, internalist view of language is
consistent with the philosophical school of "rationalism" and contrasts
with the anti-nativist, externalist view of language consistent with
the philosophical school of "empiricism",[6] which contends that all
knowledge, including language, comes from external stimuli.[7] |
ノーム・チョムスキーの言語理論の基礎は生物言語学にあ
り、言語の構造を支える原理は生物学的に人間の心にあらかじめ備わっており、それゆえ遺伝的に受け継がれるとする言語学派である[2]。
[チョムスキーはこの立場を採用するにあたり、B.F.スキナーの急進的な行動主義心理学を否定している。スキナーは、発話、思考、およびすべての行動
を、生物とその環境との相互作用から完全に学習された産物であるとみなしていた。したがって、チョムスキーは、言語はヒトという種の独自の進化的発展であ
り、他の動物種が使用するコミュニケーション様式とは区別されると主張している[4][5]。チョムスキーの自然主義的、内発主義的な言語観は「合理主
義」の哲学学派と一致しており、言語を含むすべての知識は外部からの刺激に由来すると主張する「経験主義」の哲学学派[6]と一致する反自然主義的、外発
主義的な言語観とは対照的である[7]。 |
| Universal grammar Main article: Universal grammar Since the 1960s, Chomsky has maintained that syntactic knowledge is at least partially inborn, implying that children need only learn certain language-specific features of their native languages. He bases his argument on observations about human language acquisition and describes a "poverty of the stimulus": an enormous gap between the linguistic stimuli to which children are exposed and the rich linguistic competence they attain. For example, although children are exposed to only a very small and finite subset of the allowable syntactic variants within their first language, they somehow acquire the highly organized and systematic ability to understand and produce an infinite number of sentences, including ones that have never before been uttered, in that language.[8] To explain this, Chomsky reasoned that the primary linguistic data must be supplemented by an innate linguistic capacity. Furthermore, while a human baby and a kitten are both capable of inductive reasoning, if they are exposed to exactly the same linguistic data, the human will always acquire the ability to understand and produce language, while the kitten will never acquire either ability. Chomsky referred to this difference in capacity as the language acquisition device, and suggested that linguists needed to determine both what that device is and what constraints it imposes on the range of possible human languages. The universal features that result from these constraints would constitute "universal grammar".[9][10][11] Multiple scholars have challenged universal grammar on the grounds of the evolutionary infeasibility of its genetic basis for language,[12] the lack of universal characteristics between languages,[13] and the unproven link between innate/universal structures and the structures of specific languages.[14] Scholar Michael Tomasello has challenged Chomsky's theory of innate syntactic knowledge as based on theory and not behavioral observation.[15] Although it was influential from 1960s through 1990s, Chomsky's nativist theory was ultimately rejected by the mainstream child language acquisition research community owing to its inconsistency with research evidence.[16][17] It was also argued by linguists including Geoffrey Sampson, Geoffrey K. Pullum and Barbara Scholz that Chomsky's linguistic evidence for it had been false.[18] |
普遍文法 主な記事 普遍文法 1960年代以降、チョムスキーは統語論的知識は少なくとも部分的には先天的に備わっていると主張してきた。チョムスキーは、人間の言語習得に関する観察 に基づき、「刺激の貧困」、すなわち、子どもが受ける言語刺激と、彼らが獲得する豊かな言語能力との間にある大きなギャップについて論じている。例えば、 子どもは最初の言語内で許容される構文の変種のごくわずかで有限なサブセットにしか接しないにもかかわらず、どういうわけか、その言語で、それまで一度も 発せられたことのない文も含め、無限の数の文を理解し生成する高度に組織的かつ体系的な能力を獲得する[8]。これを説明するために、チョムスキーは、一 次的な言語データは生得的な言語能力によって補完されなければならないと推論した。さらに、人間の赤ちゃんと子猫はともに帰納的推論が可能であるが、まっ たく同じ言語データにさらされた場合、人間は必ず言語を理解し生成する能力を獲得するが、子猫はどちらの能力も獲得することはない。チョムスキーは、この 能力の差を言語習得装置と呼び、言語学者はその装置が何であるか、そしてそれが人間の言語の可能性の範囲にどのような制約を課しているかを明らかにする必 要があると示唆した。これらの制約の結果として生じる普遍的な特徴は「普遍文法」を構成することになる[9][10][11]。複数の学者が、言語の遺伝 的基盤の進化論的非実現性[12]、言語間の普遍的特徴の欠如[13]、生得的/普遍的構造と特定の言語の構造との間の証明されていない関連性[14]を 理由に普遍文法に異議を唱えている。学者であるマイケル・トマセロは、生得的構文知識に関するチョムスキーの理論が行動観察ではなく理論に基づいていると して異議を唱えている[15]。 また、ジェフリー・サンプソン、ジェフリー・K・プラム、バーバラ・ショルツなどの言語学者によって、チョムスキーの言語学的根拠は誤りであると主張され ていた[18]。 |
| Transformational-generative
grammar Main articles: Transformational grammar, Generative grammar, Chomsky hierarchy, and Minimalist program Transformational-generative grammar is a broad theory used to model, encode, and deduce a native speaker's linguistic capabilities.[19] These models, or "formal grammars", show the abstract structures of a specific language as they may relate to structures in other languages.[20] Chomsky developed transformational grammar in the mid-1950s, whereupon it became the dominant syntactic theory in linguistics for two decades.[19] "Transformations" refers to syntactic relationships within language, e.g., being able to infer that the subject between two sentences is the same person.[21] Chomsky's theory posits that language consists of both deep structures and surface structures: Outward-facing surface structures relate phonetic rules into sound, while inward-facing deep structures relate words and conceptual meaning. Transformational-generative grammar uses mathematical notation to express the rules that govern the connection between meaning and sound (deep and surface structures, respectively). By this theory, linguistic principles can mathematically generate potential sentence structures in a language.[7] 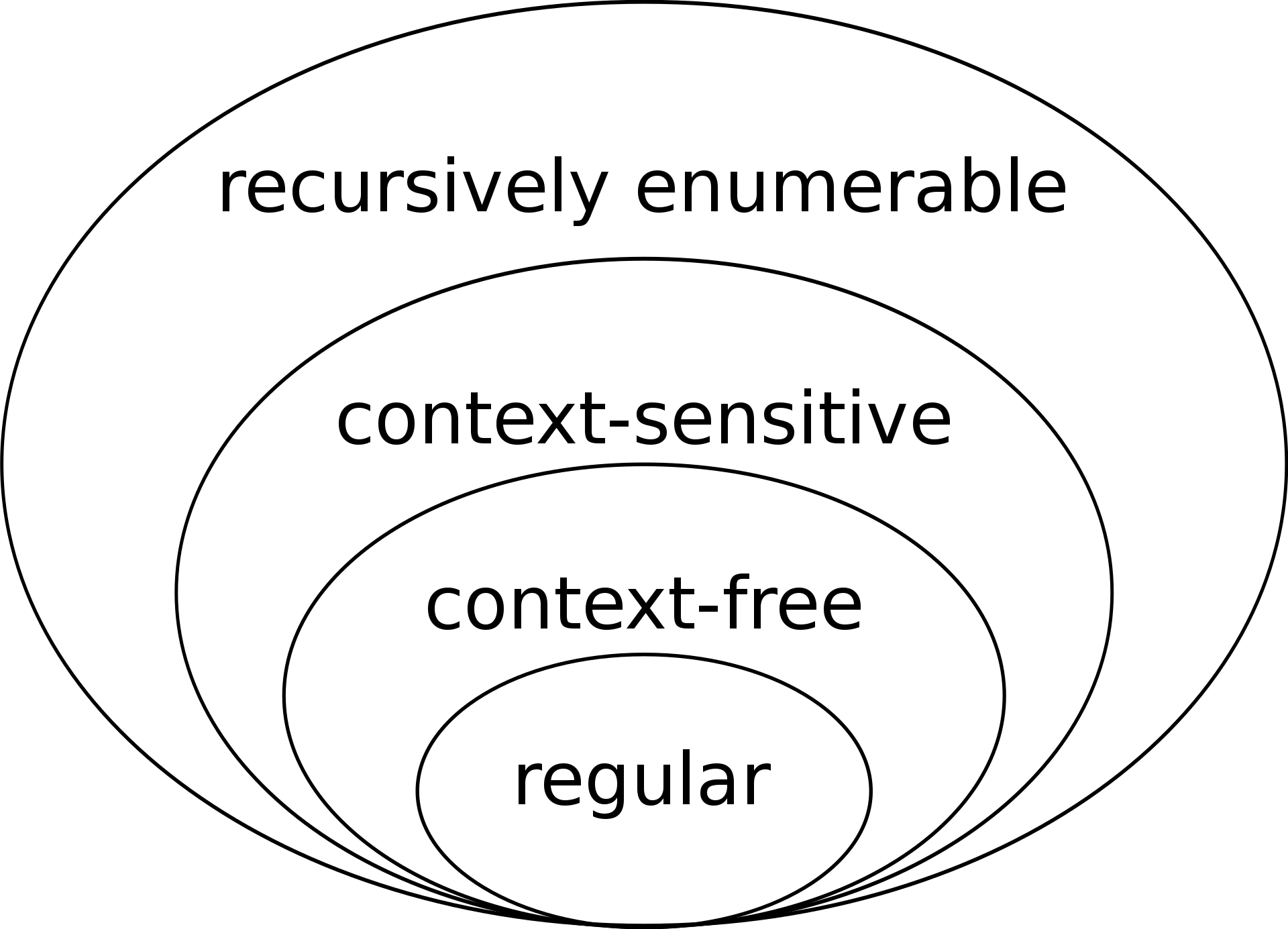 A set of 4 ovals inside one another, each resting at the bottom of the one larger than itself. There is a term in each oval; from smallest to largest: regular, context-free, context-sensitive, recursively enumerable. Set inclusions described by the Chomsky hierarchy Chomsky is commonly credited with inventing transformational-generative grammar, but his original contribution was considered modest when he first published his theory. In his 1955 dissertation and his 1957 textbook Syntactic Structures, he presented recent developments in the analysis formulated by Zellig Harris, who was Chomsky's PhD supervisor, and by Charles F. Hockett.[a] Their method is derived from the work of the Danish structural linguist Louis Hjelmslev, who introduced algorithmic grammar to general linguistics.[b] Based on this rule-based notation of grammars, Chomsky grouped logically possible phrase-structure grammar types into a series of four nested subsets and increasingly complex types, together known as the Chomsky hierarchy. This classification remains relevant to formal language theory[22] and theoretical computer science, especially programming language theory,[23] compiler construction, and automata theory.[24] Transformational grammar was the dominant research paradigm through the mid-1970s. The derivative[19] government and binding theory replaced it and remained influential through the early 1990s, [19] when linguists turned to a "minimalist" approach to grammar. This research focused on the principles and parameters framework, which explained children's ability to learn any language by filling open parameters (a set of universal grammar principles) that adapt as the child encounters linguistic data.[25] The minimalist program, initiated by Chomsky,[26] asks which minimal principles and parameters theory fits most elegantly, naturally, and simply.[25] In an attempt to simplify language into a system that relates meaning and sound using the minimum possible faculties, Chomsky dispenses with concepts such as "deep structure" and "surface structure" and instead emphasizes the plasticity of the brain's neural circuits, with which come an infinite number of concepts, or "logical forms".[5] When exposed to linguistic data, a hearer-speaker's brain proceeds to associate sound and meaning, and the rules of grammar we observe are in fact only the consequences, or side effects, of the way language works. Thus, while much of Chomsky's prior research focused on the rules of language, he now focuses on the mechanisms the brain uses to generate these rules and regulate speech.[5][27] |
変形生成文法 主な記事 変形文法、 生成文法、 チョムスキー階層、 ミニマリストプログラム 形質転換-生成文法とは、母語話者の言語能力をモデル化し、符号化し、推論するために使用される広範な理論である[19]。これらのモデル、または「形式 文法」は、特定の言語の抽象的な構造を、それらが他の言語の構造と関連する可能性があるように示す[20]、 チョムスキーの理論は、言語は深層構造と表層構造の両方から構成されていると仮定している: 外向きの表層構造は音声規則を音に関連付け、内向きの深層構造は単語と概念的意味を関連付ける。変換生成文法は、意味と音(それぞれ深層構造と表層構造) の結びつきを支配する規則を数学的表記法で表現する。この理論によって、言語原理は言語における潜在的な文構造を数学的に生成することができる[7]。 互いに内側にある4つの楕円の集合で、それぞれが自分より大きい楕円の底にある。小さいものから順に、規則的、文脈自由、文脈依存、再帰的に列挙可能であ る。 チョムスキー・ヒエラルキーで説明される集合包含体 チョムスキーは一般的に、変形生成文法を発明したと信じられているが、彼が最初に理論を発表したときには、その貢献はささやかなものだったと考えられてい る。1955年の学位論文と1957年の教科書『統語構造』において、彼はチョムスキーの博士課程の指導教官であったゼリグ・ハリスとチャールズ・F・ホ ケットによって定式化された解析の最近の発展を紹介した。 [チョムスキーはこのルールベースの文法表記法に基づいて、論理的に可能な句構造文法を4つの入れ子になった部分集合と次第に複雑になっていく文法型に分 類し、これらを合わせてチョムスキー階層と呼んだ。この分類は、形式言語理論[22]や理論計算機科学、特にプログラミング言語理論[23]、コンパイラ 構築、オートマトン理論[24]に現在も関連している。 変形文法は1970年代半ばまで支配的な研究パラダイムであった。派生的な[19]政府と束縛理論がこれに取って代わり、言語学者が文法への「ミニマリス ト」アプローチに転向した1990年代初頭まで影響力を持ち続けた[19]。この研究は、原理とパラメータの枠組みに焦点を当てたものであり、子どもが言 語データに遭遇したときに適応するオープンパラメータ(普遍的な文法原理のセット)を満たすことによって、子どもがどのような言語でも学習する能力を説明 するものであった[25]。チョムスキーによって始められたミニマリストプログラム[26]は、どの最小限の原理とパラメータ理論が最もエレガントで、自 然で、シンプルに適合するかを問うものであった。 [25]。言語を、可能な限り最小限の能力を用いて意味と音を関連付けるシステムへと単純化する試みにおいて、チョムスキーは「深層構造」や「表層構造」 といった概念を排除し、代わりに脳の神経回路の可塑性を強調する。したがって、チョムスキーの先行研究の多くが言語の規則に焦点を当てたものであったのに 対し、彼は現在、脳がこれらの規則を生成し、発話を制御するために使用するメカニズムに焦点を当てている[5][27]。 |
| Selected bibliography Main article: Noam Chomsky bibliography and filmography Linguistics Syntactic Structures (1957) Current Issues in Linguistic Theory (1964) Aspects of the Theory of Syntax (1965) Cartesian Linguistics (1965) Language and Mind (1968) The Sound Pattern of English with Morris Halle (1968) Reflections on Language (1975) Lectures on Government and Binding (1981) The Minimalist Program (1995) |
|
●自然言語処理
| 自然言語処理(しぜんげんごしょり、英語:
natural language
processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野であ
る。「計算言語学」(computational
linguistics)との類似もあるが、自然言語処理は工学的な視点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす
事が多い[1]。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な(コンピュータが理解しやすい)表現に変換するといった処理
が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。 |
|
| 自然言語の理解をコンピュータにさせることは、自然言語理解とされてい
る。自然言語理解と、自然言語処理の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解析手法(統計や確率など)が広められた為、
パーサ(統語解析器)などが一段と精度や速度が上がり、その意味合いは違ってきている。もともと自然言語の意味論的側面を全く無視して達成できることは非
常に限られている。このため、自然言語処理には形態素解析と構文解析、文脈解析、意味解析などをSyntaxなど表層的な観点から解析をする学問である
が、自然言語理解は、意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題になってきており、両者の境界は意思や意図が含まれるかど
うかになってきている。 |
|
| 自然言語処理の基礎技術にはさまざまなものがある。自然言語処理はその
性格上、扱う言語によって大きく処理の異なる部分がある。現在のところ、日本語を処理する基礎技術としては以下のものが主に研究されている。 形態素解析 構文解析 語義の曖昧性解消 照応解析 |
|
| 現状発達している言語AI技術は、多次元のベクトルから、単語や文書の
意味の近さを、その相互関係から推定しているもので、「AIの言語理解」は「人間の言語理解」は根本的に別物である[2]。 「自然言語理解は、AI完全問題と言われることがある。なぜなら、自然言語理解には世界全体についての知識とそれを操作する能力が必要と思われるためであ る。「理解; understanding」の定義は、自然言語処理の大きな課題のひとつでもある。 人間とコンピュータの間のインタラクションのインタフェース(ヒューマンマシンインタフェース)として、自然言語がもし使えたら非常に魅力的である、と いったこともあり、コンピュータの登場初期(1960年頃)には自然言語処理にある種の過剰な期待もあった。SHRDLUなどの初期のシステムが、世界を 限定することで非常にうまくいったことにより、すぐに行き過ぎた楽観主義に陥ったが、現実を相手にする曖昧さや複雑さがわかると、楽観的な見方や過剰な期 待は基本的には無くなったが、何が簡単で何が難しいのか、といったようなことはなかなか共有されなかった。 やがて、21世紀に入ってしばらく後に「音声認識による便利なシステム」がいくつか実用化・実運用され多くの人が利用したことで、何が簡単で、どういう事 に使うのは難しいのかが理解されるようになりつつある模様である。 2019年、GPT-2、BERTなど、ディープラーニングを応用した手法で大きなブレークスルーがあった。 |
|
| 自然言語処理(理解)における課題をいくつかの例を用いて示す。 次の2つの文、 We gave the monkeys the bananas because they were hungry.(猿が腹を空かせていたので、バナナを与えた。) We gave the monkeys the bananas because they were over-ripe.(バナナは熟れ過ぎていたので、猿に与えた。) は、品詞としては全く同じ順序の並びである。しかし、they が指すものは異なっていて、前者では猿、後者ではバナナとなっている。この例文の場合、theyの指す内容は英語の文型の性質によって決定することができ る。すなわち、「they(主語)= hungry(補語)」の関係が成り立ち、補語には主語の性質を示すものがくるので、hungryなのはthe monkeys、したがって、「they = the monkeys」と決まる。後者も同様に、over-ripeというのはthe bananasの性質だから、「they = the bananas」となる。つまり、これらの文章を区別し正しく理解するためには、意味、すなわち、猿の性質(猿は動物で空腹になる)とバナナの性質(バナ ナは果物で成熟する)といったことを知っていて解釈できなければならない。 |
|
| 単語の文字列を解釈する方法は様々である。例えば、 Time flies like an arrow.(光陰矢の如し) という文字列は以下のように様々に解釈できる。 典型的には、比喩として、「時間が矢のように素早く過ぎる」と解釈する。 「空を飛ぶ昆虫の速度を矢の速度を測るように測定せよ」つまり (You should) time flies as you would (time) an arrow. と解釈する。 「矢が空を飛ぶ昆虫の速度を測るように、あなたが空を飛ぶ昆虫の速度を測定せよ」つまり Time flies in the same way that an arrow would (time them). と解釈する。 「矢のように空を飛ぶ昆虫の速度を測定せよ」つまり Time those flies that are like arrows と解釈する。 「"time-flies"(時バエ)という種類の昆虫は1つの矢を好む」この解釈には集合的な解釈と個別的解釈がありうる。 「TIMEという雑誌は、投げると直線的な軌跡を描く」 英語では特に語形変化による語彙の区別をする機能が弱いため、このような問題が大きくなる。 また、英語も含めて、形容詞と名詞の修飾関係の曖昧さもある。例えば、"pretty little girls' school"(かわいい小さな少女の学校)という文字列があるとする。 その学校は小さいだろうか? 少女たちが小さいのだろうか? 少女たちがかわいいのだろうか? 学校がかわいいのだろうか? 他にも次のような課題がある。 |
|
| 形態素解析 中国語、日本語、タイ語といった言語は単語のわかち書きをしない。そのため、単語の区切りを特定するのにテキストの解析が必要となり、それは非常に複雑な 作業となる。 |
|
| 音声における形態素解析 音声言語において、文字を表す音は前後の音と混じっているのが普通である。従って音声から文字を切り出すのは、非常に難しい作業となる。さらに、音声言語 では単語と単語の区切りも(音としてのみ見れば)定かではなく、文脈や文法や意味といった情報を考慮しないと単語を切り出せない。 |
|
| 語義の曖昧性 多くの単語は複数の意味を持つ。従って、特定の文脈においてもっともふさわしい意味を選択する必要がある。 |
|
| 構文の曖昧性 自然言語の構文(構文規則)は曖昧である。1つの文に対応する複数の構文木が存在することも多い。もっとも適切な解釈(構文木)を選択するには、意味的情 報や文脈情報を必要とする。 |
|
| 不完全な入力や間違った入力 主語の省略や代名詞の対応などの問題(照応解析)。音声におけるアクセントのばらつき。構文上の誤りのある文の解析。光学文字認識における誤りの認識な ど。 |
|
| 言語行為 文章は文字通りに解釈できない場合がある。例えば "Can you pass the salt?"(塩をとってもらえますか?)という問いに対する答えは、塩を相手に渡すことである。これに "Yes" とだけ答えて何もしないのはよい答えとは言えないが、"No" はむしろありうる答えで、"I'm afraid that I can't see it" はさらによい(塩がどこにあるかわからないとき)。 |
|
| 統計的自然言語処理 統計的自然言語処理は、確率論的あるいは統計学的手法を使って、上述の困難さに何らかの解決策を与えようとするものである。長い文になればなるほど、従来 型の自然言語処理では解釈の可能性の組合せが指数関数的に増大していき、処理が困難となる。そのような場合に統計的自然言語処理が効果を発揮する。コーパ ス言語学やマルコフ連鎖といった手法が使われる。統計的自然言語処理の起源は、人工知能の中でもデータからの学習を研究する分野である機械学習やデータマ イニングといった分野である。 |
|
| 自然言語処理の応用技術として、以下のような技術が研究・実用化されて
いる。また、言語学への応用も考えられている。 自動要約生成 情報抽出 情報検索、検索エンジン、概念検索 機械翻訳、翻訳ソフト 固有表現抽出 自然言語生成 光学文字認識 質問応答システム 音声認識 音声合成 校正、スペルチェッカ かな漢字変換 |
|
| https://bit.ly/3BPAQ03. |
+++
リンク
文献
その他の情報

Copyleft, CC, Mitzub'ixi Quq Chi'j, 1996-2099

++
Copyleft, CC, Mitzub'ixi Quq Chi'j, 1996-2099
![]()
☆
 ☆
☆