ソース・コード
Source Code
ソース・コード
Source Code
****コンピューティングでは、ソースコード、または単にコード、ソースは、プログラミン
グ言語で書かれたプレーンテキストのコンピュータプログラムである。プログラマーは、コンピュータの動作を制御するために、人間が読めるソースコードを書
く。
コンピュータは基本的にマシン・コードしか理解できないため、ソース・コードはコンピュータが実行する前に翻訳されなければならない。翻訳プロセスには3
つの方法がある。ソースコードをコンパイラやアセンブラで機械語に変換する。その結果得られる実行可能ファイルは、コンピュータがすぐに使えるマシン・
コードとなる。あるいは、インタープリターを使ってソースコードを変換せずに実行することもできる。インタープリターはソースコードをメモリにロードす
る。インタープリターは同時に各ステートメントを翻訳し、実行する。コンパイルと解釈を組み合わせた方法としては、まずバイトコードを生成する。バイト
コードはソースコードの中間表現であり、すぐに解釈される。
| In computing, source code,
or simply code or source, is a plain text computer program written in a
programming language. A programmer writes the human readable source
code to control the behavior of a computer. Since a computer, at base, only understands machine code, source code must be translated before a computer can execute it. The translation process can be implemented three ways. Source code can be converted into machine code by a compiler or an assembler. The resulting executable is machine code ready for the computer. Alternatively, source code can be executed without conversion via an interpreter. An interpreter loads the source code into memory. It simultaneously translates and executes each statement. A method that combines compilation and interpretation is to first produce bytecode. Bytecode is an intermediate representation of source code that is quickly interpreted. |
コンピューティングでは、ソースコード、または単にコード、ソースは、
プログラミング言語で書かれたプレーンテキストのコンピュータプログラムである。プログラマーは、コンピュータの動作を制御するために、人間が読めるソー
スコードを書く。 コンピュータは基本的にマシン・コードしか理解できないため、ソース・コードはコンピュータが実行する前に翻訳されなければならない。翻訳プロセスには3 つの方法がある。ソースコードをコンパイラやアセンブラで機械語に変換する。その結果得られる実行可能ファイルは、コンピュータがすぐに使えるマシン・ コードとなる。あるいは、インタープリターを使ってソースコードを変換せずに実行することもできる。インタープリターはソースコードをメモリにロードす る。インタープリターは同時に各ステートメントを翻訳し、実行する。コンパイルと解釈を組み合わせた方法としては、まずバイトコードを生成する。バイト コードはソースコードの中間表現であり、すぐに解釈される。 |
| Background The first programmable computers, which appeared at the end of the 1940s,[2] were programmed in machine language (simple instructions that could be directly executed by the processor). Machine language was difficult to debug and was not portable between different computer systems.[3] Initially, hardware resources were scarce and expensive, while human resources were cheaper.[4] As programs grew more complex, programmer productivity became a bottleneck. This led to the introduction of high-level programming languages such as Fortran in the mid-1950s. These languages abstracted away the details of the hardware, instead being designed to express algorithms that could be understood more easily by humans.[5][6] As instructions distinct from the underlying computer hardware, software is therefore relatively recent, dating to these early high-level programming languages such as Fortran, Lisp, and Cobol.[6] The invention of high-level programming languages was simultaneous with the compilers needed to translate the source code automatically into machine code that can be directly executed on the computer hardware.[7] Source code is the form of code that is modified directly by humans, typically in a high-level programming language. Object code can be directly executed by the machine and is generated automatically from the source code, often via an intermediate step, assembly language. While object code will only work on a specific platform, source code can be ported to a different machine and recompiled there. For the same source code, object code can vary significantly—not only based on the machine for which it is compiled, but also based on performance optimization from the compiler.[8][9] |
背景 1940年代末に登場した最初のプログラマブル・コンピュータ[2]は、機械語(プロセッサが直接実行できる単純な命令)でプログラムされていた。機械語 はデバッグが難しく、異なるコンピュータシステム間での移植性がなかった[3]。当初、ハードウェア資源は不足していて高価であったが、人的資源は安価で あった[4]。このため、1950年代半ばにFortranのような高水準プログラミング言語が導入された。これらの言語はハードウェアの詳細を抽象化 し、その代わりに人間がより理解しやすいアルゴリズムを表現するように設計された[5][6]。そのため、基礎となるコンピュータハードウェアとは異なる 命令として、ソフトウェアは比較的新しく、Fortran、Lisp、Cobolなどの初期の高水準プログラミング言語にまでさかのぼる[6]。高水準プ ログラミング言語の発明は、ソースコードをコンピュータハードウェア上で直接実行できるマシンコードに自動的に翻訳するために必要なコンパイラと同時だっ た[7]。 ソースコードとは、人間が直接修正するコードのことで、一般的には高級プログラミング言語で記述される。オブジェクト・コードは、マシンで直接実行するこ とができ、ソース・コードから、多くの場合、中間ステップであるアセンブリ言語を経由して自動的に生成される。オブジェクト・コードは特定のプラット フォームでしか動作しないが、ソース・コードは別のマシンに移植し、そこで再コンパイルすることができる。同じソースコードであっても、オブジェクトコー ドは、コンパイルされるマシンだけでなく、コンパイラによるパフォーマンスの最適化によっても大きく異なる可能性がある[8][9]。 |
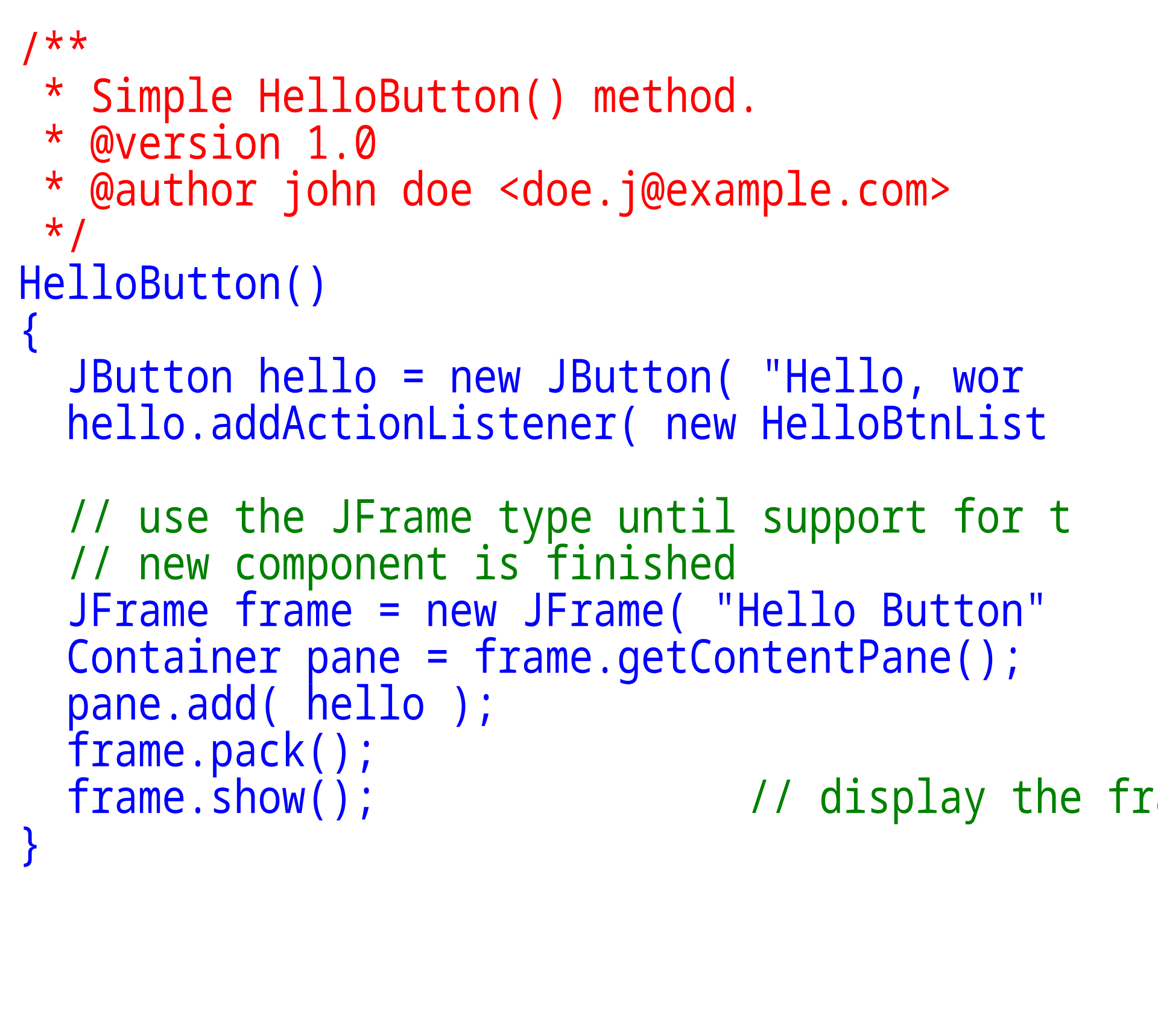
| Organization Main article: Software configuration management Most programs do not contain all the resources needed to run them and rely on external libraries. Part of the compiler's function is to link these files in such a way that the program can be executed by the hardware.[10] A more complex Java source code example. Written in object-oriented programming style, it demonstrates boilerplate code. With prologue comments indicated in red, inline comments indicated in green, and program statements indicated in blue. Software developers often use configuration management to track changes to source code files (version control). The configuration management system also keeps track of which object code file corresponds to which version of the source code file.[11] |
組織 主な記事 ソフトウェア構成管理 ほとんどのプログラムは、実行に必要なすべてのリソースを含んでおらず、外部ライブラリに依存している。コンパイラの機能の一部は、プログラムがハード ウェアで実行できるように、これらのファイルをリンクすることである[10]。 より複雑なJavaソースコードの例。オブジェクト指向プログラミングスタイルで書かれ、定型的なコードを示している。プロローグ・コメントは赤、インラ イン・コメントは緑、プログラム・ステートメントは青で示されている。 ソフトウェア開発者は、ソースコード・ファイルの変更を追跡するために、しばしば構成管理を使用する(バージョン管理)。コンフィギュレーション管理シス テムは、どのオブジェクト・コード・ファイルがソース・コード・ファイルのどのバージョンに対応しているかも追跡する[11]。 |
 |
|
| Purposes Estimation The number of lines of source code is often used as a metric when evaluating the productivity of computer programmers, the economic value of a code base, effort estimation for projects in development, and the ongoing cost of software maintenance after release.[12] Communication Source code is also used to communicate algorithms between people – e.g., code snippets online or in books.[13] Computer programmers may find it helpful to review existing source code to learn about programming techniques.[13] The sharing of source code between developers is frequently cited as a contributing factor to the maturation of their programming skills.[13] Some people consider source code an expressive artistic medium.[14] Source code often contains comments—blocks of text marked for the compiler to ignore. This content is not part of the program logic, but is instead intended to help readers understand the program.[15] Companies often keep the source code confidential in order to hide algorithms considered a trade secret. Proprietary, secret source code and algorithms are widely used for sensitive government applications such as criminal justice, which results in black box behavior with a lack of transparency into the algorithm's methodology. The result is avoidance of public scrutiny of issues such as bias.[16] Modification See also: Software development and Software maintenance Access to the source code (not just the object code) is essential to modifying it.[17] Understanding existing code is necessary to understand how it works[17] and before modifying it.[18] The rate of understanding depends both on the code base as well as the skill of the programmer.[19] Experienced programmers have an easier time understanding what the code does at a high level.[20] Software visualization is sometimes used to speed up this process.[21] Many software programmers use an integrated development environment (IDE) to improve their productivity. IDEs typically have several features built in, including a source-code editor that can alert the programmer to common errors.[22] Modification often includes code refactoring (improving the structure without changing functionality) and restructuring (improving structure and functionality at the same time). [23] Nearly every change to code will introduce new bugs or unexpected ripple effects, which require another round of fixes.[18] Code reviews by other developers are often used to scrutinize new code added to a project.[24] The purpose of this phase is often to verify that the code meets style and maintainability standards and that it is a correct implementation of the software design.[25] According to some estimates, code review dramatically reduce the number of bugs persisting after software testing is complete.[24] Along with software testing that works by executing the code, static program analysis uses automated tools to detect problems with the source code. Many IDEs support code analysis tools, which might provide metrics on the clarity and maintainability of the code.[26] Debuggers are tools that often enable programmers to step through execution while keeping track of which source code corresponds to each change of state.[27] Compilation and execution Source code files in a high-level programming language must go through a stage of preprocessing into machine code before the instructions can be carried out.[7] After being compiled, the program can be saved as an object file and the loader (part of the operating system) can take this saved file and execute it as a process on the computer hardware.[10] Some programming languages use an interpreter instead of a compiler. An interpreter converts the program into machine code at run time, which makes them 10 to 100 times slower than compiled programming languages.[22][28] |
目的 見積もり ソースコードの行数は、コンピュータプログラマの生産性、コードベースの経済的価値、開発中のプロジェクトの労力見積もり、リリース後のソフトウェアメン テナンスの継続的なコストを評価する際の指標としてよく使われる[12]。 コミュニケーション ソースコードは、オンラインや書籍のコード・スニペットなど、人々の間でアルゴリズムを伝達するためにも使用される[13]。 コンピュータ・プログラマは、プログラミング技法について学ぶために、既存のソース・コードをレビューすることが役に立つと感じるかもしれない[13]。 開発者間でソース・コードを共有することは、プログラミング・スキルの成熟に貢献する要因として頻繁に挙げられる[13]。ソース・コードを表現力豊かな 芸術的媒体だと考える人もいる[14]。 ソース・コードには、コンパイラが無視するようにマークされたコメント・ブロックが含まれていることが多い。この内容はプログラムのロジックの一部ではな く、読者がプログラムを理解するのを助けるためのものである[15]。 企業は、企業秘密とされるアルゴリズムを隠すために、ソースコードを秘密にすることが多い。独占的な秘密のソースコードとアルゴリズムは、刑事司法などの 機密性の高い政府アプリケーションに広く使用されており、その結果、アルゴリズムの方法論に対する透明性が欠如したブラックボックス的な動作になってい る。その結果、バイアスのような問題についての公的な精査が避けられることになる[16]。 修正 以下も参照のこと: ソフトウェア開発、ソフトウェア保守 ソースコード(オブジェクトコードだけでなく)にアクセスすることは、それを修正するために不可欠である[17]。既存のコードを理解することは、それが どのように動作するかを理解するために必要であり[17]、それを修正する前に必要である[18]。 多くのソフトウェアプログラマは、生産性を向上させるために統合開発環境(IDE)を使用している。IDEには通常、プログラマに一般的なエラーを警告す るソースコードエディタなど、いくつかの機能が組み込まれている[22]。修正にはしばしば、コードのリファクタリング(機能を変えずに構造を改善するこ と)やリストラクチャリング(構造と機能を同時に改善すること)が含まれる。[23]コードへのほぼすべての変更は、新たなバグや予期せぬ波及効果をもた らすので、別のラウンドの修正が必要になる[18]。 他の開発者によるコードレビューは、プロジェクトに追加された新しいコードを精査するためによく使用される[24]。このフェーズの目的は、コードがスタ イルと保守性の基準を満たしているか、ソフトウェア設計の正しい実装であるかを検証することであることが多い[25]。いくつかの試算によると、コードレ ビューは、ソフトウェアテストが完了した後に残るバグの数を劇的に減らす[24]。コードを実行することで機能するソフトウェアテストとともに、静的プロ グラム解析は、ソースコードの問題を検出するために自動化されたツールを使用する。多くのIDEはコード解析ツールをサポートしており、コードの明瞭性と 保守性についてのメトリクスを提供することができる[26]。デバッガは、プログラマが各状態変化に対応するソースコードを追跡しながら、実行をステップ 実行できるようにするツールであることが多い[27]。 コンパイルと実行 高水準プログラミング言語のソースコード・ファイルは、命令を実行する前に機械語コードに前処理する段階を経なければならない[7]。コンパイルされた 後、プログラムはオブジェクト・ファイルとして保存することができ、ローダー(オペレーティング・システムの一部)はこの保存されたファイルを受け取り、 コンピュータのハードウェア上でプロセスとして実行することができる[10]。インタプリタは実行時にプログラムを機械語に変換するため、コンパイルされ たプログラミング言語よりも10倍から100倍遅い[22][28]。 |
| Quality Main article: Software quality Software quality is an overarching term that can refer to a code's correct and efficient behavior, its reusability and portability, or the ease of modification.[29] It is usually more cost-effective to build quality into the product from the beginning rather than try to add it later in the development process.[30] Higher quality code will reduce lifetime cost to both suppliers and customers as it is more reliable and easier to maintain.[31][32] Maintainability is the quality of software enabling it to be easily modified without breaking existing functionality.[33] Following coding conventions such as using clear function and variable names that correspond to their purpose makes maintenance easier.[34] Use of conditional loop statements only if the code could execute more than once, and eliminating code that will never execute can also increase understandability.[35] Many software development organizations neglect maintainability during the development phase, even though it will increase long-term costs.[32] Technical debt is incurred when programmers, often out of laziness or urgency to meet a deadline, choose quick and dirty solutions rather than build maintainability into their code.[36] A common cause is underestimates in software development effort estimation, leading to insufficient resources allocated to development.[37] A challenge with maintainability is that many software engineering courses do not emphasize it.[38] Development engineers who know that they will not be responsible for maintaining the software do not have an incentive to build in maintainability.[18] |
品質 主な記事 ソフトウェアの品質 ソフトウェア品質とは、コードの正しく効率的な動作、再利用性と移植性、または修正の容易さを指す包括的な用語である[29]。通常、開発プロセスの後半 で品質を追加しようとするよりも、最初から製品に品質を組み込んだ方が費用対効果が高い[30]。より高品質なコードは信頼性が高く保守が容易であるた め、サプライヤーと顧客の双方にとって生涯コストを削減できる[31][32]。 保守性とは、既存の機能を壊すことなく、容易に修正できるソフトウェアの品質である[33]。目的に対応する明確な関数名や変数名を使用するなどのコー ディング規約を守ることで、保守が容易になる[34]。コードが複数回実行される可能性がある場合にのみ条件付きループ文を使用し、実行されることのない コードを排除することも、理解しやすさを高めることができる[35]。 [32] 技術的負債は、プログラマが、多くの場合、怠慢や納期に間に合わせる緊急性から、保守性をコードに組み込むのではなく、手っ取り早く汚い解決策を選択した ときに発生する[36]。 よくある原因は、ソフトウェア開発工数の見積もりが過小評価され、開発に割り当てられるリソースが不足することである[37]。 |
| Copyright and licensing Main articles: Software copyright and Software license See also: History of free and open-source software The situation varies worldwide, but in the United States before 1974, software and its source code was not copyrightable and therefore always public domain software.[39] In 1974, the US Commission on New Technological Uses of Copyrighted Works (CONTU) decided that "computer programs, to the extent that they embody an author's original creation, are proper subject matter of copyright".[40][41] Proprietary software is rarely distributed as source code.[42] Although the term open-source software literally refers to public access to the source code,[43] open-source software has additional requirements: free redistribution, permission to modify the source code and release derivative works under the same license, and nondiscrimination between different uses—including commercial use.[44][45] The free reusability of open-source software can speed up development.[46] |
著作権とライセンス 主な記事 ソフトウェア著作権、ソフトウェアライセンス も参照のこと: フリーソフトウェアとオープンソースソフトウェアの歴史 1974年、米国の著作物の新技術利用委員会(CONTU)は、「コンピュータ・プログラムは、著作者の独創的な創作を具現化する限りにおいて、著作権の 適切な主題である」と決定した[40][41]。 プロプライエタリなソフトウェアがソースコードとして配布されることはほとんどない[42]。オープンソースソフトウェアという用語は、文字通りソース コードへの一般公開を意味するが[43]、オープンソースソフトウェアには、自由な再配布、ソースコードを修正し、同じライセンスの下で派生作品をリリー スする許可、商業利用を含む異なる用途間の無差別という追加要件がある[44][45]。オープンソースソフトウェアの自由な再利用性は、開発を加速させ ることができる[46]。 |
| Bytecode Code as data Coding conventions Free software Legacy code Machine code Markup language Obfuscated code Object code Open-source software Package (package management system) Programming language Source code repository Syntax highlighting Visual programming language |
バイトコード データとしてのコード コーディング規約 フリーソフトウェア レガシーコード マシン・コード マークアップ言語 難読化コード オブジェクトコード オープンソース・ソフトウェア パッケージ(パッケージ管理システム) プログラミング言語 ソースコード・リポジトリ シンタックス・ハイライト ビジュアル・プログラミング言語 |
| https://en.wikipedia.org/wiki/Source_code |
リンク
リンク(フィールドワーク)
文献
その他の情報
