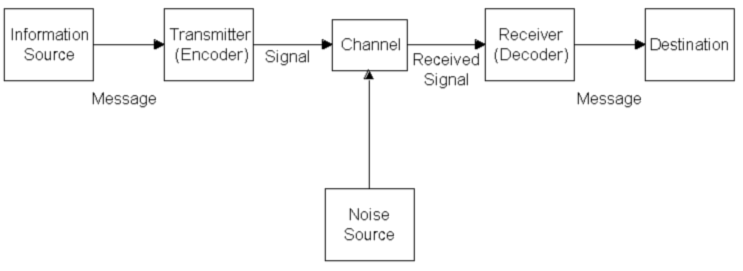
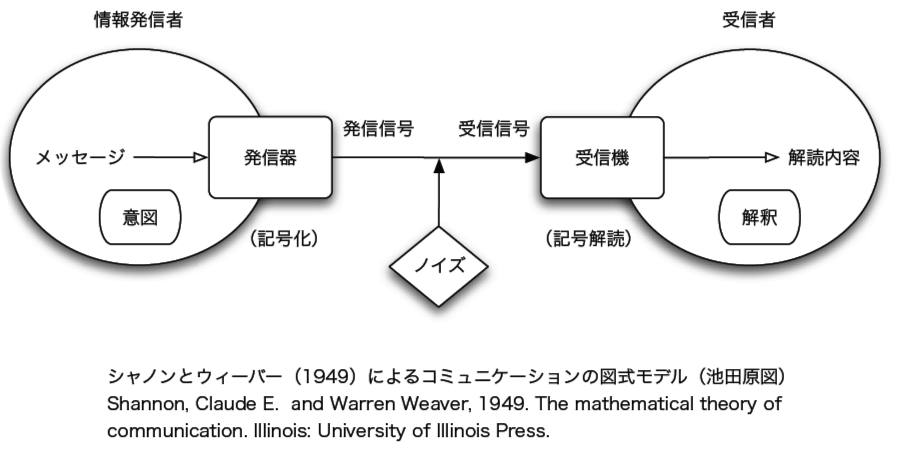
●機械学習の手法
人工知能ビジネス基本用語集
Artificial intelligence, AI
解説:池田光穂
●人工知能(AI)ビジネス基本用語集
| コンピュータが得意なこと |
コンピュータが苦手なこと |
1)高速で正確な計算 2)正確に情報を伝える 3)膨大な情報を誤りなく記録する |
1)複雑な外部世界を認識する 2)言語を理解し、現実の世界の現象と関連づける 3)因果関係を推論する |
| 解説(谷田部卓『これからのAIビジネ
ス』MdN, 2018年による) |
池田コメント |
|
| 人工知能 |
「言語の理解や推論、問題解決など知的行
動を人間にかわってコンピュータに行わせる技術」 |
これでいいのか? |
| ディープラーニング | ディープ・ラーニングとは「パラメーター
化され多モジュールを相互接続したネットワーク(グラフ)に適用される学習方法の総称。学習では、勾配降下法をつかってモジュールのパラメーターを修正す
る。通常、勾配は誤差逆伝播法によって得られる。多層ニューラルネットワークの訓練は、ディーブラーニングの一例である」(ルカン 2021:376) |
ディープラーニング学習する機械 : ヤン・ルカン、人工知能を語る / Yann LeCun著 ; 小川浩一訳, 講談社 , 2021.→第1章 AI革命 第2章 AIならびに私の小史 第3章 単純な学習機械 第4章 最小化学習、学習理論 第5章 深層ニューラルネットワークと誤差逆伝播法 第6章 AIの支柱、ニューラルネットワーク 第7章 ディープラーニングの現在 第8章 Facebook時代 第9章 そして明日は?AIの今後と課題 第10章 AIの問題点 |
| 機械学習 | ||
| 教師あり学習 |
機械学習の手法のひとつ。あらかじめ正解
のデータ(教師データ)を必要とする。教師データからパターンや特徴を学習させる |
|
| 教師なし学習 |
||
| 強化学習 |
||
| 自然言語処理 |
||
| ニューラルネットワーク |
ニュー
ラルネットワーク(神経網, neural network;
NN)は「入力を線形変換する処理単位」がネットワーク状に結合した数理モデルである。人工ニューラルネットワーク (英: artificial
neural network) とも言う。 |
|
| 生成モデル |
教師データをもとにして、そのデータと似
たような新しいデータを創り出すモデルのこと |
|
| GAN, Generative
Advisarial Network |
生成器Gと識別器Dの間の2つのディープ
ラーニングで構成されたモデルのこと |
|
| 過学習 |
機械学習において教師あり学習をおこなっ
た際に、未学習の問題に対して正しく答えをだせない状態 |
|
| スパースモデリング: |
少ない情報からデータの全体像を的確に抽
出する(どのようにして?)科学的モデリング。疎性モデリングともいう |
Sparse
approximation: "theory
deals with sparse solutions for systems of linear equations. Techniques
for finding these solutions and exploiting them in applications have
found wide use in image processing, signal processing, machine
learning, medical imaging, and more." |
| PoC: Proof of
Concept |
新しい概念や理論、原理などの実証を目的
とした実験 |
|
| フィンテック |
||
| 仮想通貨 |
||
| ブロックチェーン |
「ブロックチェーン(英語:
Blockchain)とは、分散型台帳技術、または、分散型ネットワークである。ブロックチェインとも。ビットコインの中核技術(ナカモト・サトシ=
Satoshi Nakamotoが 開発)を原型とするデータベースである。ブ
ロックと呼ばれる順序付けられたレコードの連続的に増加するリストを持つ。各ブロックには、タイムスタンプと前のブロックへのリンクが含まれている。理論上、一度記録する
と、ブロック内のデータを遡及的に変更することはできない。ブロックチェーンデータベースは、 Peer to
Peerネットワークと分散型タイムスタンプサーバーの使用により、自律的に管理される」- Wiki,ブロックチェーン。 |
|
| IoT |
||
| HRテック: Human
Resource Technology |
||
| マーケティング・オートメーション |
||
| RPA: Robotic
Process Autometion |
||
| SDGs |
||
| Society 5.0 |
Critique of Japanese
govenment's developing concept of "Society 5.0"; |
|
| セマンンティック・セグメンテーション |
||
| 記号接地 |
||
| ダートマス会議(1956) |
●機械学習の手法
| 単純ベイズ法 |
単純ベイズ分類器(たんじゅんベイズぶんるいき、英:
Naive Bayes
classifier)は、単純な確率的分類器である。単純ベイズ分類器の元となる確率モデルは強い(単純な)独立性仮定と共にベイズの定理を適用するこ
とに基づいており、より正確に言えば「独立特徴モデル; independent feature
model」と呼ぶべきものである。確率モデルの性質に基づいて、単純ベイズ分類器は教師あり学習の設定で効率的に訓練可能である。多くの実用例では、単
純ベイズ分類器のパラメータ推定には最尤法が使われる。つまり、単純ベイズ分類器を使用するにあたって、ベイズ確率やその他のベイズ的手法を使う必要はな
い。設計も仮定も非常に単純であるにも関わらず、単純ベイズ分類器は複雑な実世界の状況において、期待よりもずっとうまく働く。近頃、ベイズ分類問題の注
意深い解析によって、単純ベイズ分類器の効率性に理論的理由があることが示された[1]。単純ベイズ分類器の利点は、分類に不可欠なパラメータ(変数群の
平均と分散)を見積もるのに、訓練例データが少なくて済む点である。変数群は独立であると仮定されているため、各クラスについての変数の分散だけが必要で
あり、共分散行列全体は不要である。 |
| 最大エントロピー法 |
最大エントロピー原理(さいだいエントロピーげんり、英:
principle of maximum
entropy)は、認識確率分布を一意に定めるために利用可能な情報を分析する手法である。この原理を最初に提唱したのは Edwin
Thompson Jaynes
である。彼は1957年に統計力学のギブズ分布を持ち込んだ熱力学(最大エントロピー熱力学(英語版))を提唱した際に、この原理も提唱したものである。
彼は、熱力学やエントロピーは、情報理論や推定の汎用ツールの応用例と見るべきだと示唆した。他のベイズ的手法と同様、最大エントロピー原理でも事前確率
を明示的に利用する。これは古典的統計学における推定手法の代替である。 |
| ロジスティック回帰モデル |
ロジスティック回帰(ロジスティックかいき、英: Logistic
regression)は、ベルヌーイ分布に従う変数の統計的回帰モデルの一種である。連結関数としてロジットを使用する一般化線形モデル (GLM)
の一種でもある。1958年にデイヴィッド・コックス(英語版)が発表した[1]。確率の回帰であり、統計学の分類に主に使われる。医学や社会科学でもよ
く使われる。ロジスティック回帰モデルは同じく1958年に発表された単純パーセプトロンと等価であるが、scikit-learnなどでは、パラメータ
を決める最適化問題で確率的勾配降下法を使用する物をパーセプトロンと呼び、座標降下法や準ニュートン法などを使用する物をロジスティック回帰と呼んでい
る。 |
| アダブースト |
AdaBoost(Adaptive
Boosting、エイダブースト、アダブースト)は、Yoav Freund と Robert Schapire
によって考案された機械学習アルゴリズムである。
メタアルゴリズムであり、他の多くの学習アルゴリズムと組み合わせて利用することで、そのパフォーマンスを改善することができる。 |
| サポートベクターマシーン |
ポートベクターマシン(英: support-vector
machine,
SVM)は、教師あり学習を用いるパターン認識モデルの1つである。分類や回帰へ適用できる。1963年にウラジミール・ヴァプニク(英語版)と
Alexey Ya. Chervonenkisが線形サポートベクターマシンを発表し[1]、1992年にBernhard E.
Boser、Isabelle M.
Guyon、ウラジミール・ヴァプニクが非線形へと拡張した。サポートベクターマシンは、現在知られている手法の中でも認識性能が優れた学習モデルの1つ
である。サポートベクターマシンが優れた認識性能を発揮することができる理由は、未学習データに対して高い識別性能を得るための工夫があるためである。 |
| 条件付き確率場 |
条件付き確率場(じょうけんつきかくりつば、英語:
Conditional random field、略称:
CRF)は無向グラフにより表現される確率的グラフィカルモデルの一つであり、識別モデル()である。これは自然言語処理、生体情報工学、コンピュータビ
ジョンなどの分野で連続データの解析などによく利用される。特にCRFは形態素解析、固有表現抽出、ゲノミクスに応用され、隠れマルコフモデルに関連する
ような問題において、代わりとしても用いることができる。コンピュータビジョンにおいては、物体認識、画像領域分割(セグメンテーション)などに使用され
る。 |
リンク
文献
その他の情報
++
Copyleft, CC,
Mitzub'ixi Quq Chi'j, 1997-2099
