ハイパーテキスト
Hypertext
ハイパーテキスト
Hypertext
ハイパーテキストとは、ディスプレイ上の情報に関連する情報を、ディスプレイから直接アクセ スできるデータベース形式のことである。つまり、ハイパーテキストとはデータベース(database)のことである(→ 「インターテクスチュアリティ」「ハイパーメディア」)。Hypertext is "a database format in which information related to that on a display can be accessed directly from the display". d Free Online
この、d Free Online の定義のすごいところは、ハイパーテキストを「単に下線がありそこをク リックすると別のページに飛べる」というアホな記述に終わっているのではないことだ。つまりハイパーテキストの言葉の正しい定義は、通常のテキストにマルチリンクが埋め込まれるとそれ(=ハイパーテキスト)は《関連するデータベースが埋め込まれたフォーマット》に化けるということを的確に 示していることである。他方でハイパーテキストは「インターネットの粘着性=固 着性」の原理からみると、別のところにユーザーを誘うという点ではリスクがあるが、それがサイト内や関連する「連携サイト」の中だけでのデータ ベースアクセスを達成すれば、サイトに対するユーザーへの「粘着性」は高まるということになる(ウィキペディアやWikiwandの成功はここにある)。それは「サイト内に誘う=ハイパーリンクする情報が多ければ多いほど」粘着性の高いメディアになることは 容易に推論できる。それ自体が多言語の情報データーベースであるWikipediaはウィキ文法というハイ パーテキスト表示によりすばらしい粘着性の実践をおこなっている点で、私たちの優良 なビジネスの見本になっている。他方、グーグルやヤフーは、世界のインターネットのあらゆる情報に(AIとクッキー技術を使って)繋がると いう特性を利用して、粘着性を自分のサイトにおくのではなく、世界のサイトそのもの の情報ポータル検索ツールとしてユーザーを強力に囲い込む点で、ハイパーテキスト産業のうち、世界でもっとも成功したもののふたつであろ う。
★記号論(記号学)におけるハイパーテキストならびにハイポテキストの概念
| Hypertext,
in semiotics, is a text which alludes to, derives from, or relates to
an earlier work or hypotext (a subsequent of a hypotext).[1] For example, James Joyce's Ulysses could be regarded as one of the many hypertexts deriving from Homer's Odyssey; Angela Carter's "The Tiger's Bride" can be considered a hypertext which relates to an earlier work, or hypotext, the original fairy-story Beauty and the Beast. Hypertexts may take a variety of forms including imitation, parody, and pastiche. The word was defined by the French theorist Gérard Genette as follows: "Hypertextuality refers to any relationship uniting a text B (which I shall call the hypertext) to an earlier text A (I shall, of course, call it the hypotext), upon which it is grafted in a manner that is not that of commentary."[2] So, a hypertext derives from hypotext(s) through a process which Genette calls transformation, in which text B "evokes" text A without necessarily mentioning it directly ".[3] Note that this technical use of the word in semiotics differs from its use in the field of computing, although the two are related. Liestøl's study of Genette's narratological model and hyperfiction considers how they are related and suggests that hyperfiction narratives have four levels:[4] 1. Discourse as discoursed; 2. Discourse as stored; 3. Story as discoursed; 4. Stories as stored (potential story lines). References Martin, Bronwen (2006). Key Terms in Semiotics. Continuum. p. 99. Genette, Gérard (1997). Palimpsests: Literature in the Second Degree. U of Nebraska Press. p. 5. Herman, David (1998). Palimpsests: Literature in the Second Degree (review). MFS Modern Fiction Studies. pp. 1043–8. Liestøl, Gunnar (1994). "Wittgenstein, Genette, and the Reader's Narrative in Hypertext". In Landow, George P. (ed.). Hyper/Text/Theory. Johns Hopkins UP. p. 97. https://en.wikipedia.org/wiki/Hypertext_(semiotics) |
ハイパーテキストとは、記号論において、以前の作品やハイポテキスト
(ハイポテキストの後続)を暗示、派生、関連するテキストのことである[1]。 例えば、ジェイムズ・ジョイスの『ユリシーズ』は、ホメロスの『オデッセイ』から派 生した数多くのハイパーテキストのひとつとみなすことができる。アン ジェラ・カーターの『虎の花嫁』は、それ以前の作品、つまりハイポテキストである童話『美女と野獣』に関連するハイパーテキストとみなすことができる。ハ イパーテキストには、模倣、パロディ、パスティーシュなど、さまざまな形態がある(→「イ ンターテクスチュアリティ」)。 この言葉は、フランスの理論家ジェラール・ジュネットによって次のように定義された: 「ハイパーテキスト性とは、テキストB(これをハイパーテキストと呼ぶことにする)を、以前のテキストA(もちろん、これをハイポテキストと呼ぶことにす る)と結びつけるあらゆる関係を指す。 記号論におけるこの言葉の技術的な用法は、コンピューティングの分野での用法とは異なるが、両者は関連していることに注意されたい。ジェネットのナラトロ ジー・モデルとハイパーフィクションに関するリーステルの研究は、両者がどのように関連しているかを考察し、ハイパーフィクションの語りには次の4つのレ ベルがあることを示唆している[4]。 1. ディスコースとしての言説; 2. 保存される言説 3. 談話としての物語; 4. 保存されたストーリー(潜在的なストーリーライン)。 文献 References Martin, Bronwen (2006). Key Terms in Semiotics. Continuum. p. 99. Genette, Gérard (1997). Palimpsests: Literature in the Second Degree. U of Nebraska Press. p. 5. Herman, David (1998). Palimpsests: Literature in the Second Degree (review). MFS Modern Fiction Studies. pp. 1043–8. Liestøl, Gunnar (1994). "Wittgenstein, Genette, and the Reader's Narrative in Hypertext". In Landow, George P. (ed.). Hyper/Text/Theory. Johns Hopkins UP. p. 97. |
| Hypotext
is an earlier text which serves as the source of a subsequent piece of
literature, or hypertext.[1] For example, Homer's Odyssey could be
regarded as the hypotext for James Joyce's Ulysses. The word was defined by the French theorist Gérard Genette as follows "Hypertextuality refers to any relationship uniting a text B (which I shall call the hypertext) to an earlier text A (I shall, of course, call it the hypotext), upon which it is grafted in a manner that is not that of commentary."[2] So, a hypertext derives from hypotext(s) through a process which Genette calls transformation, in which text B "evokes" text A without necessarily mentioning it directly. The hypertext may of course become original text in its own right.[3] The word has more recently been used in extended ways, for example, Adamczewski suggests that the Iliad was used as a structuring hypotext in Mark's Gospel.[4] References Martin, Bronwen (2006). Key Terms in Semiotics. Continuum. p. 100. ISBN 0-8264-8456-5. Retrieved 5 August 2013. Genette, Gérard (1997). Palimpsests: Literature in the Second Degree. U of Nebraska Press. p. 5. Allen, Graham (2013). The New Critical Idiom. Ch 3: Hypertextuality.: Routledge. Adamczewski, Bartosz (2010). Q Or Not Q?: The So-Called Triple, Double, and Single Traditions in the Synoptic Gospels. Peter Lang. p. 269. https://en.wikipedia.org/wiki/Hypotext |
例えば、ホメロスの『オデュッセイア』は、ジェイムズ・ジョイスの『ユ
リシーズ』のハイポテキストとみなすことができる。 「ハイパーテキスト性とは、テキストB(これをハイパーテキストと呼ぶことにする)を、解説ではない方法で接ぎ木された以前のテキストA(もちろん、これを ハイポテキストと呼ぶことにする)と結びつけるあらゆる関係を指す」[2]。 つまり、ハイパーテキストは、ジュネットが「変換」と呼ぶプロセスを通じてハイポテキストから派生するのであり、その際、テキストBは必ずしもテキストA に直接言及することなく、テキストAを「喚起」する。もちろん、ハイパーテキストはそれ自体がオリジナルのテキストになることもある[3]。 例えば、アダムチェフスキは『イーリアス』がマルコの福音書において構造化するハイポテキストとして使用されたことを示唆している[4]。 References Martin, Bronwen (2006). Key Terms in Semiotics. Continuum. p. 100. ISBN 0-8264-8456-5. Retrieved 5 August 2013. Genette, Gérard (1997). Palimpsests: Literature in the Second Degree. U of Nebraska Press. p. 5. Allen, Graham (2013). The New Critical Idiom. Ch 3: Hypertextuality.: Routledge. Adamczewski, Bartosz (2010). Q Or Not Q?: The So-Called Triple, Double, and Single Traditions in the Synoptic Gospels. Peter Lang. p. 269. |
☆ハイポテキスト
| Hypotext is an
earlier text which serves as the source of a subsequent piece of
literature, or hypertext.[1] For example, Homer's Odyssey could be
regarded as the hypotext for James Joyce's Ulysses. The word was defined by the French theorist Gérard Genette as follows "Hypertextuality refers to any relationship uniting a text B (which I shall call the hypertext) to an earlier text A (I shall, of course, call it the hypotext), upon which it is grafted in a manner that is not that of commentary."[2] So, a hypertext derives from hypotext(s) through a process which Genette calls transformation, in which text B "evokes" text A without necessarily mentioning it directly. The hypertext may of course become original text in its own right.[3] The word has more recently been used in extended ways, for example, Adamczewski suggests that the Iliad was used as a structuring hypotext in Mark's Gospel.[4] |
ハイポテキストとは、その後の文学作品やハイパーテキストの源となる以前のテキストのことです[1]。例えば、ホメロスの『オデュッセイア』は、ジェームズ・ジョイスの『ユリシーズ』のハイポテキストと見なすことができます。 この用語は、フランスの理論家ジェラール・ジェネットによって次のように定義されている。「ハイパーテキスト性とは、テキストB(これをハイパーテキスト と呼ぶ)と、それよりも前のテキストA(当然ながらこれをヒポテキストと呼ぶ)との間に存在する関係であり、その関係は、コメントのような形でテキストB に組み込まれるものではない。」[2] したがって、ハイパーテキストは、ジェネットが「変換」と呼ぶプロセスを通じて、ハイポテキストから派生し、テキストBはテキストAを直接言及することなく「喚起」する。ハイパーテキストは、もちろん、独自のオリジナルテキストとなる可能性もある。[3] この用語は最近、より広範な意味で用いられるようになった。例えば、アダムチェフスキは、マルコの福音書において、イリアスが構造化のためのハイポテキストとして用いられたと示唆している。[4] |
| 1.Martin, Bronwen (2006). Key Terms in Semiotics. Continuum. p. 100. ISBN 0-8264-8456-5. Retrieved 5 August 2013. 2. Genette, Gérard (1997). Palimpsests: Literature in the Second Degree. U of Nebraska Press. p. 5. 3. Allen, Graham (2013). The New Critical Idiom. Ch 3: Hypertextuality.: Routledge. 4. Adamczewski, Bartosz (2010). Q Or Not Q?: The So-Called Triple, Double, and Single Traditions in the Synoptic Gospels. Peter Lang. p. 269. |
1.マーティン、ブロンウェン (2006)。『記号論のキーワード』。Continuum。100 ページ。ISBN 0-8264-8456-5。2013年8月5日取得。 2. ジェネット、ジェラール (1997)。『パリンプセスト:第二度の文学』。ネブラスカ大学出版。5 ページ。 3. アレン、グラハム (2013)。新しい批評用語。第 3 章:ハイパーテキスト性。Routledge。 4. アダムチェフスキ、バルトシュ (2010)。Q それとも Q ではない?:共観福音書におけるいわゆる三重、二重、単一の伝統。ピーター・ラング。269 ページ。 |
| https://en.wikipedia.org/wiki/Hypotext |
★インターネットにおけるテクスト概念の話に、戻ってみよう。
Hypertext is "a database format in which information
related to that on a display can be accessed directly from the display".
d Free
Online
Since hyper- generally means "above, beyond", hypertext is something that's gone beyond the limitations of ordinary text. Thus, unlike the text in a book, hypertext permits you, by clicking with a mouse, to immediately access text in one of millions of different electronic sources. Hypertext is now so familiar that most computer users may not even know the word, which was coined by Ted Nelson back in the early 1960s. It took a few more years for hypertext to actually be created, by Douglas Engelbart, and then quite a few more years before the introduction of the World Wide Web in 1991. First Known Use of hypertext was in1965.
hyper-は一般的に「上の、超えた」という意味
なので、ハイパーテキストは、通常のテキストの限界を超えたものである。本の中の文章とは異なり、ハイパーテキストでは、マウスでクリックするだけで、何
百万もの異なる電子ソースの中の文章にすぐにアクセスすることができる。ハイパーテキストという言葉は、1960年代初頭にテッド・ネルソンが作ったもので、今ではほとんどのコンピューターユーザーが知
らないほど身近なものになっている。ハイパーテキストが実際に作られたのは、ダグラ
ス・エンゲルバートによるもので、1991年にWorld Wide
Webが登場するまでには、さらに数年を要したという。ハイパーテキストが初めて使われたのは1965年のことである。
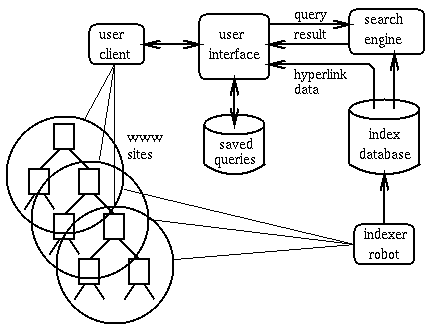
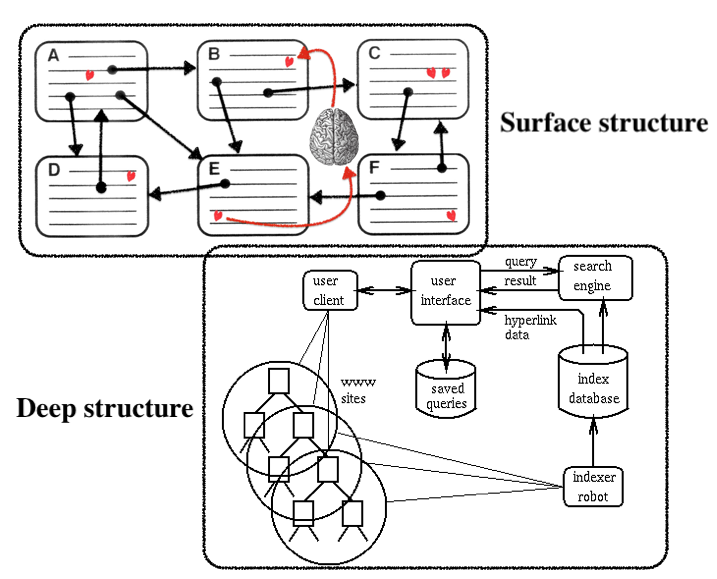
Encyclopedia of Knowledge Organization, https://www.isko.org/cyclo/hypertext A World Wide Web Resource Discovery System, Figure 1. The WWW Resource Discovery System's architecture.
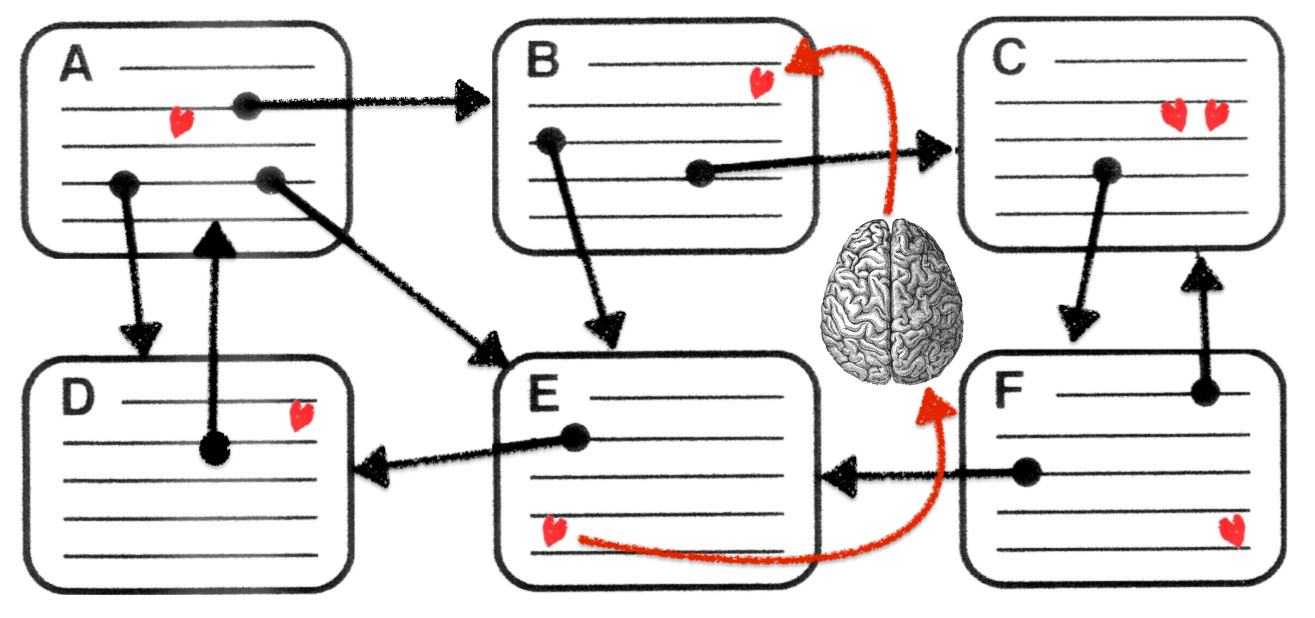
Sergey Brin and
Lawrence Page (1998:111) (→「美学的
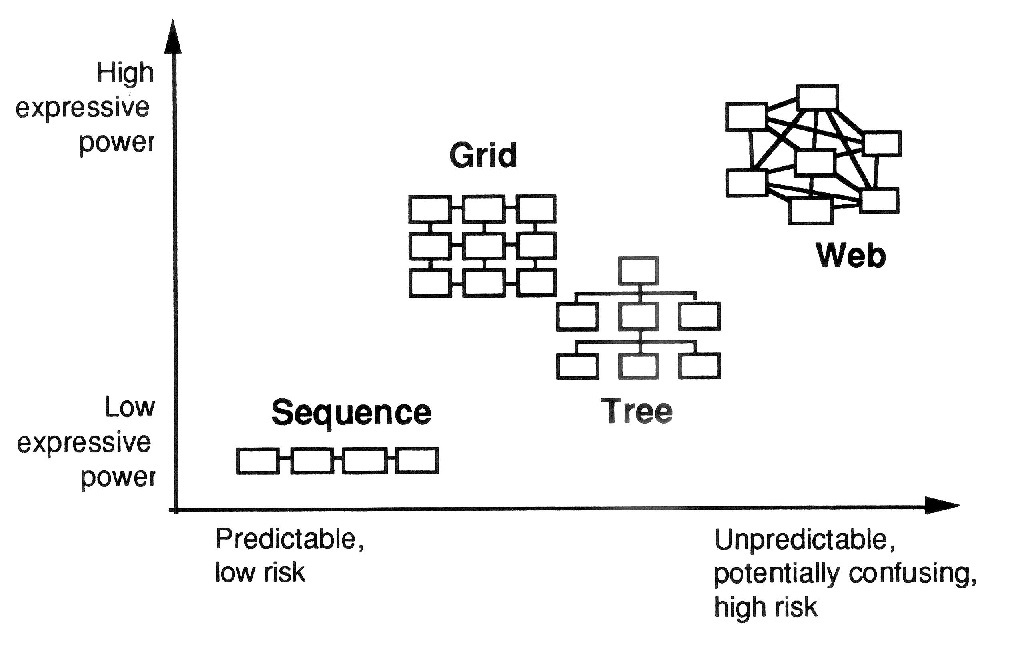
コミュニケーションとは?」) Figure 7: Sequence, grid, tree, web (from Brockmann,
Horton and Brock 1989, 183)
◎データベースとは?
コンピュータにおいて、デー タベースとは、電子的に保存され、アクセスされるデータの組織化された集合体で ある。小規模なデータベースはファイルシステム上に保存でき、大規模なデータベースはコンピュータクラスタやクラウドストレージにホストされる。データ ベースの設計は、データモデリング、効率的なデータ表現と保存、クエリー言語、機密データのセキュリティとプライバシー、同時アクセスやフォールトトレラ ンスのサポートなどの分散コンピューティングの問題など、形式手法と実際の考察にまたがるものである。
| In computing, a database is
an organized collection of data stored and accessed
electronically. Small databases can be stored on a file system, while
large databases are hosted on computer clusters or cloud storage. The
design of databases spans formal techniques and practical
considerations, including data modeling, efficient data representation
and storage, query languages, security and privacy of sensitive data,
and distributed computing issues, including supporting concurrent
access and fault tolerance. A database management system (DBMS) is the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS software additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database. Computer scientists may classify database management systems according to the database models that they support. Relational databases became dominant in the 1980s. These model data as rows and columns in a series of tables, and the vast majority use SQL for writing and querying data. In the 2000s, non-relational databases became popular, collectively referred to as NoSQL, because they use different query languages. |
コンピュータにおいて、データベースとは、電子的に保存され、アクセスされるデータの組織化された集合体で
ある。小規模なデータベースはファイルシステム上に保存でき、大規模なデータベースはコンピュータクラスタやクラウドストレージにホストされる。データ
ベースの設計は、データモデリング、効率的なデータ表現と保存、クエリー言語、機密データのセキュリティとプライバシー、同時アクセスやフォールトトレラ
ンスのサポートなどの分散コンピューティングの問題など、形式手法と実際の考察にまたがるものである。 データベース管理システム(DBMS)は、エンドユーザー、アプリケー ション、データベースそのものと対話し、データを取得・分析するためのソフトウェアで ある。DBMSソフトウェアは、さらに、データベースを管理するために提供される中核的な機能を包含している。データベース、DBMS、関連アプリケー ションの総称をデータベースシステムと呼ぶことができる。多くの場合、「データベース」という用語は、DBMS、データベースシステム、またはデータベー スに関連するアプリケーションのいずれかを指す場合にも緩やかに使用される。 コンピュータ科学者は、データベース管理システムを、それがサポートするデータベースモデルによって分類することができる。リレーショナルデータベースは 1980 年代に主流となった。このデータベースは、データを一連のテーブルの行と列としてモデル化し、大多数はデータの書き込みと問い合わせにSQLを使用してい る。2000年代には、非リレーショナルデータベースが普及し、異なる問い合わせ言語を使用することから、総称してNoSQLと呼ばれるようになった。 |
| Terminology and overview Formally, a "database" refers to a set of related data and the way it is organized. Access to this data is usually provided by a "database management system" (DBMS) consisting of an integrated set of computer software that allows users to interact with one or more databases and provides access to all of the data contained in the database (although restrictions may exist that limit access to particular data). The DBMS provides various functions that allow entry, storage and retrieval of large quantities of information and provides ways to manage how that information is organized. Because of the close relationship between them, the term "database" is often used casually to refer to both a database and the DBMS used to manipulate it. Outside the world of professional information technology, the term database is often used to refer to any collection of related data (such as a spreadsheet or a card index) as size and usage requirements typically necessitate use of a database management system.[1] Existing DBMSs provide various functions that allow management of a database and its data which can be classified into four main functional groups: Data definition – Creation, modification and removal of definitions that define the organization of the data. Update – Insertion, modification, and deletion of the actual data.[2] Retrieval – Providing information in a form directly usable or for further processing by other applications. The retrieved data may be made available in a form basically the same as it is stored in the database or in a new form obtained by altering or combining existing data from the database.[3] Administration – Registering and monitoring users, enforcing data security, monitoring performance, maintaining data integrity, dealing with concurrency control, and recovering information that has been corrupted by some event such as an unexpected system failure.[4] Both a database and its DBMS conform to the principles of a particular database model.[5] "Database system" refers collectively to the database model, database management system, and database.[6] Physically, database servers are dedicated computers that hold the actual databases and run only the DBMS and related software. Database servers are usually multiprocessor computers, with generous memory and RAID disk arrays used for stable storage. Hardware database accelerators, connected to one or more servers via a high-speed channel, are also used in large volume transaction processing environments. DBMSs are found at the heart of most database applications. DBMSs may be built around a custom multitasking kernel with built-in networking support, but modern DBMSs typically rely on a standard operating system to provide these functions.[citation needed] Since DBMSs comprise a significant market, computer and storage vendors often take into account DBMS requirements in their own development plans.[7] Databases and DBMSs can be categorized according to the database model(s) that they support (such as relational or XML), the type(s) of computer they run on (from a server cluster to a mobile phone), the query language(s) used to access the database (such as SQL or XQuery), and their internal engineering, which affects performance, scalability, resilience, and security. |
用語と概要 形式的には、「データベース」とは、関連するデータの集合と、その編成方法を指す。このデータへのアクセスは通常、「データベース管理システム」 (DBMS)によって提供される。このシステムは、ユーザーが1つまたは複数のデータベースと対話し、データベースに含まれるすべてのデータへのアクセス を可能にする統合されたコンピュータソフトウェアのセットで構成されている(ただし、特定のデータへのアクセスを制限する制約が存在する場合もある)。 DBMSは、大量の情報の入力、保存、検索を可能にする様々な機能を提供し、その情報がどのように組織化されているかを管理する方法を提供する。 このように両者は密接な関係にあるため、「データベース」という言葉は、データベースとそれを操作するためのDBMSの両方を指す言葉として気軽に使われ ることが多い。 専門的な情報技術の世界以外では、データベースという用語は、関連するデータの集まり(スプレッドシートやカードインデックスなど)を指すことが多く、サ イズや使用要件からデータベース管理システムを使用することが一般的である[1]。 既存のDBMSは、データベースとそのデータを管理するための様々な機能を提供しており、それらは4つの主要な機能群に分類することができる。 データ定義 - データの構成を定義する定義の作成、変更、削除。 更新 - 実際のデータの挿入、変更、削除[2]。 検索 - 情報を直接利用可能な形で、または他のアプリケーションでさらに処理できるように提供すること。検索されたデータは、基本的にデータベースに格納されてい るのと同じ形態で利用可能になる場合もあれば、データベースから既存のデータを変更したり組み合わせたりして得られた新しい形態で利用可能になる場合もあ る[3]。 管理 - ユーザーの登録と監視、データセキュリティの実施、パフォーマンスの監視、データの整合性の維持、同時実行制御の処理、予期せぬシステム障害など何らかの 事象によって破損した情報の回復など[4]。 データベースとその DBMS はともに、特定のデータベースモデルの原則に準拠している[5]。「データベースシステム」は、データベースモデル、データベース管理システム、および データベースを総称している[6]。 物理的には、データベースサーバーは実際のデータベースを保持し、DBMSと関連ソフトウェアのみを実行する専用コンピュータである。データベースサー バーは通常マルチプロセッサーであり、メモリに余裕があり、安定した保存のためにRAIDディスクアレイが使用される。大容量トランザクション処理環境で は、1台または複数台のサーバーと高速チャネルで接続されたハードウェアデータベースアクセラレータも使用される。DBMSは、ほとんどのデータベースア プリケーションの中核をなしている。DBMSはネットワークサポートを内蔵したカスタムのマルチタスクカーネルを中心に構築されることもあるが、最近の DBMSは通常、これらの機能を提供するために標準的なオペレーティングシステムに依存している[citation needed]。 DBMSは重要な市場を構成しているため、コンピュータとストレージのベンダーはしばしば自らの開発計画にDBMSの要件を取り込んでいる[7]。 データベースと DBMS は、サポートするデータベースモデル(リレーショナルや XML など)、実行するコンピュータの種類(サーバークラスタから携帯電話まで)、データベースへのアクセスに使用するクエリー言語(SQL や XQuery など)、性能、拡張性、回復力、セキュリティに影響する内部エンジニアリングによって分類することができる。 |
| History The sizes, capabilities, and performance of databases and their respective DBMSs have grown in orders of magnitude. These performance increases were enabled by the technology progress in the areas of processors, computer memory, computer storage, and computer networks. The concept of a database was made possible by the emergence of direct access storage media such as magnetic disks, which became widely available in the mid-1960s; earlier systems relied on sequential storage of data on magnetic tape. The subsequent development of database technology can be divided into three eras based on data model or structure: navigational,[8] SQL/relational, and post-relational. The two main early navigational data models were the hierarchical model and the CODASYL model (network model). These were characterized by the use of pointers (often physical disk addresses) to follow relationships from one record to another. The relational model, first proposed in 1970 by Edgar F. Codd, departed from this tradition by insisting that applications should search for data by content, rather than by following links. The relational model employs sets of ledger-style tables, each used for a different type of entity. Only in the mid-1980s did computing hardware become powerful enough to allow the wide deployment of relational systems (DBMSs plus applications). By the early 1990s, however, relational systems dominated in all large-scale data processing applications, and as of 2018 they remain dominant: IBM Db2, Oracle, MySQL, and Microsoft SQL Server are the most searched DBMS.[9] The dominant database language, standardized SQL for the relational model, has influenced database languages for other data models.[citation needed] Object databases were developed in the 1980s to overcome the inconvenience of object–relational impedance mismatch, which led to the coining of the term "post-relational" and also the development of hybrid object–relational databases. The next generation of post-relational databases in the late 2000s became known as NoSQL databases, introducing fast key–value stores and document-oriented databases. A competing "next generation" known as NewSQL databases attempted new implementations that retained the relational/SQL model while aiming to match the high performance of NoSQL compared to commercially available relational DBMSs. |
歴史 データベースとそのDBMSの規模、機能、性能は桁違いに大きくなってきた。これらの性能向上は、プロセッサー、コンピューターメモリー、コンピューター ストレージ、コンピューターネットワークなどの技術進歩によって可能となった。データベースの概念は、1960年代半ばに広く普及した磁気ディスクのよう な直接アクセス可能な記憶媒体の出現によって実現された。データベース技術のその後の発展は、データモデルや構造に基づいて、ナビゲーショナル、SQL/ リレーショナル、ポストリレーショナルという3つの時代に分けることができる[8]。 初期のナビゲーション型データモデルとしては、階層型とCODASYL型(ネットワーク型)の2つが主流であった。これらは、あるレコードから別のレコー ドへの関係をたどるために、ポインタ(多くの場合、物理的なディスクアドレス)を使用することを特徴としていた。 1970年にEdgar F. Coddが提唱したリレーショナルモデルは、この伝統から脱却し、アプリケーションはリンクをたどるのではなく、内容からデータを探すべきであると主張す るもので あった。リレーショナルモデルは、台帳型のテーブルを組み合わせて、それぞれが異なる種類のエンティティに使用される。1980年代半ばにようやく、コン ピュータのハードウェアがリレーショナルシステム(DBMSとアプリケーション)を広く展開できるほど強力になった。しかし、1990年代初頭には、大規 模なデータ処理アプリケーションのすべてにおいてリレーショナルシステムが主流となり、2018年現在も主流であり続けている。IBM Db2、Oracle、MySQL、Microsoft SQL Serverが最も検索されているDBMSである[9]。 支配的なデータベース言語であるリレーショナルモデル用の標準SQLは、他のデータモデル用のデータベース言語にも影響を与えている[引用者注:要注 意]。 オブジェクトデータベースは1980年代にオブジェクトとリレーのインピーダンス不整合の不都合を克服するために開発され、「ポストリレーショナル」とい う言葉が生まれ、またオブジェクトとリレーのハイブリッドデータベースが開発されるに至った。 2000年代後半のポストリレーショナルデータベースの次世代は、高速なキーバリューストアやドキュメント指向のデータベースを導入し、NoSQLデータ ベースと呼ばれるようになった。これと競合する「次世代」のNewSQLデータベースは、リレーショナル/SQLモデルを維持しつつ、市販のリレーショナ ルDBMSと比較してNoSQLの高い性能に見合うような新しい実装を試みている。 |
| 1960s, navigational DBMS The introduction of the term database coincided with the availability of direct-access storage (disks and drums) from the mid-1960s onwards. The term represented a contrast with the tape-based systems of the past, allowing shared interactive use rather than daily batch processing. The Oxford English Dictionary cites a 1962 report by the System Development Corporation of California as the first to use the term "data-base" in a specific technical sense.[10] As computers grew in speed and capability, a number of general-purpose database systems emerged; by the mid-1960s a number of such systems had come into commercial use. Interest in a standard began to grow, and Charles Bachman, author of one such product, the Integrated Data Store (IDS), founded the Database Task Group within CODASYL, the group responsible for the creation and standardization of COBOL. In 1971, the Database Task Group delivered their standard, which generally became known as the CODASYL approach, and soon a number of commercial products based on this approach entered the market. The CODASYL approach offered applications the ability to navigate around a linked data set which was formed into a large network. Applications could find records by one of three methods: 1 Use of a primary key (known as a CALC key, typically implemented by hashing) 2. Navigating relationships (called sets) from one record to another 3. Scanning all the records in a sequential order Later systems added B-trees to provide alternate access paths. Many CODASYL databases also added a declarative query language for end users (as distinct from the navigational API). However, CODASYL databases were complex and required significant training and effort to produce useful applications. IBM also had its own DBMS in 1966, known as Information Management System (IMS). IMS was a development of software written for the Apollo program on the System/360. IMS was generally similar in concept to CODASYL, but used a strict hierarchy for its model of data navigation instead of CODASYL's network model. Both concepts later became known as navigational databases due to the way data was accessed: the term was popularized by Bachman's 1973 Turing Award presentation The Programmer as Navigator. IMS is classified by IBM as a hierarchical database. IDMS and Cincom Systems' TOTAL databases are classified as network databases. IMS remains in use as of 2014.[11] |
1960年代、航法型DBMS データベースという言葉が登場したのは、1960年代半ば以降、直接ア クセス可能なストレージ(ディスクやドラム缶)が利用できるようになった時期と重なる。この言葉は、かつてのテープベースのシステムとは対照的で、日々の バッチ処理ではなく、対話的な共有利用を可能にするものであった。オックスフォード英語辞典では、「データベース」という用語を特定の技術的な意味で初め て使用したものとして、カリフォルニア州のシステム開発社の1962年の報告書を挙げている[10]。 コンピュータの速度と性能が向上するにつれて、多くの汎用データベースシステムが登場し、1960年代半ばには、そのようなシステムの多くが商業的に使用 されるようになった。標準化への関心が高まり、その1つである統合データストア(IDS)の作者であるチャールズ・バックマンは、COBOLの作成と標準 化を担当するCODASYLにデータベースタスクグループを設立した。1971年、データベース・タスク・グループは、一般にCODASYLアプローチと して知られるようになった彼らの標準を提供し、すぐにこのアプローチに基づいた多くの商用製品が市場に出てきた。 CODASYL方式は、アプリケーションに、大きなネットワークに形成されたリンクされたデータセット内を移動する機能を提供するものであった。アプリ ケーションは、3つの方法のうちの1つによってレコードを見つけることができる。 1. 主キーの使用(CALCキーとして知られ、典型的にはハッシュ化によって実装される)。 2. 1つのレコードから別のレコードへの関係(セットと呼ばれる)をナビゲートする。 3. すべてのレコードを順番にスキャンする。 後のシステムでは、B-treeが追加され、別のアクセス経路が提供されるようになった。多くのCODASYLデータベースは、エンドユーザー向けに(ナ ビゲーションAPIとは異なる)宣言型のクエリー言語も追加している。しかし、CODASYLデータベースは複雑で、有用なアプリケーションを作るにはか なりの訓練と労力が必要でした。 IBMも1966年に独自のDBMSを持っており、情報管理システム(IMS)として知られていた。IMSはSystem/360上のApolloプログ ラムのために書かれたソフトウェアを発展させたものであった。IMSは一般にCODASYLとコンセプトが似ているが、データナビゲーションのモデルに CODASYLのネットワークモデルではなく、厳密な階層を使用していた。この言葉は、1973年にバックマンが発表したチューリング賞の「The Programmer as Navigator」によって一般化した。IMSはIBMによって階層型データベースとして分類されている。IDMSやCincom SystemsのTOTALデータベースは、ネットワークデータベースに分類される。IMSは2014年現在も使用されている[11]。 |
| 1970s, relational DBMS Edgar F. Codd worked at IBM in San Jose, California, in one of their offshoot offices that were primarily involved in the development of hard disk systems. He was unhappy with the navigational model of the CODASYL approach, notably the lack of a "search" facility. In 1970, he wrote a number of papers that outlined a new approach to database construction that eventually culminated in the groundbreaking A Relational Model of Data for Large Shared Data Banks.[12] In this paper, he described a new system for storing and working with large databases. Instead of records being stored in some sort of linked list of free-form records as in CODASYL, Codd's idea was to organize the data as a number of "tables", each table being used for a different type of entity. Each table would contain a fixed number of columns containing the attributes of the entity. One or more columns of each table were designated as a primary key by which the rows of the table could be uniquely identified; cross-references between tables always used these primary keys, rather than disk addresses, and queries would join tables based on these key relationships, using a set of operations based on the mathematical system of relational calculus (from which the model takes its name). Splitting the data into a set of normalized tables (or relations) aimed to ensure that each "fact" was only stored once, thus simplifying update operations. Virtual tables called views could present the data in different ways for different users, but views could not be directly updated. Codd used mathematical terms to define the model: relations, tuples, and domains rather than tables, rows, and columns. The terminology that is now familiar came from early implementations. Codd would later criticize the tendency for practical implementations to depart from the mathematical foundations on which the model was based. The use of primary keys (user-oriented identifiers) to represent cross-table relationships, rather than disk addresses, had two primary motivations. From an engineering perspective, it enabled tables to be relocated and resized without expensive database reorganization. But Codd was more interested in the difference in semantics: the use of explicit identifiers made it easier to define update operations with clean mathematical definitions, and it also enabled query operations to be defined in terms of the established discipline of first-order predicate calculus; because these operations have clean mathematical properties, it becomes possible to rewrite queries in provably correct ways, which is the basis of query optimization. There is no loss of expressiveness compared with the hierarchic or network models, though the connections between tables are no longer so explicit. In the hierarchic and network models, records were allowed to have a complex internal structure. For example, the salary history of an employee might be represented as a "repeating group" within the employee record. In the relational model, the process of normalization led to such internal structures being replaced by data held in multiple tables, connected only by logical keys. For instance, a common use of a database system is to track information about users, their name, login information, various addresses and phone numbers. In the navigational approach, all of this data would be placed in a single variable-length record. In the relational approach, the data would be normalized into a user table, an address table and a phone number table (for instance). Records would be created in these optional tables only if the address or phone numbers were actually provided. As well as identifying rows/records using logical identifiers rather than disk addresses, Codd changed the way in which applications assembled data from multiple records. Rather than requiring applications to gather data one record at a time by navigating the links, they would use a declarative query language that expressed what data was required, rather than the access path by which it should be found. Finding an efficient access path to the data became the responsibility of the database management system, rather than the application programmer. This process, called query optimization, depended on the fact that queries were expressed in terms of mathematical logic. Codd's paper was picked up by two people at Berkeley, Eugene Wong and Michael Stonebraker. They started a project known as INGRES using funding that had already been allocated for a geographical database project and student programmers to produce code. Beginning in 1973, INGRES delivered its first test products which were generally ready for widespread use in 1979. INGRES was similar to System R in a number of ways, including the use of a "language" for data access, known as QUEL. Over time, INGRES moved to the emerging SQL standard. IBM itself did one test implementation of the relational model, PRTV, and a production one, Business System 12, both now discontinued. Honeywell wrote MRDS for Multics, and now there are two new implementations: Alphora Dataphor and Rel. Most other DBMS implementations usually called relational are actually SQL DBMSs. In 1970, the University of Michigan began development of the MICRO Information Management System[13] based on D.L. Childs' Set-Theoretic Data model.[14][15][16] MICRO was used to manage very large data sets by the US Department of Labor, the U.S. Environmental Protection Agency, and researchers from the University of Alberta, the University of Michigan, and Wayne State University. It ran on IBM mainframe computers using the Michigan Terminal System.[17] The system remained in production until 1998. |
1970年代、リレーショナルDBMS エドガー・F・コッドは、カリフォルニア州サンノゼのIBMで、主にハードディスクシステムの開発に携わっていた分室の1つに勤めていた。彼は、 CODASYLアプローチのナビゲーションモデル、特に「検索」機能がないことに不満を持っていた。1970年、彼はデータベース構築への新しいアプロー チを概説する多くの論文を書き、最終的に画期的な「大規模共有データバンクのためのデータのリレーショナルモデル」[12]で結実した。 この論文で、彼は大規模なデータベースを保存し、利用するための新しいシステムを説明しました。CODASYLのようにレコードをある種の自由形式のリン クリストに格納するのではなく、コッドのアイデアは、データをいくつかの「テーブル」として整理し、それぞれのテーブルを異なるタイプのエンティティに使 用することであった。各テーブルは、エンティティの属性を含む固定数のカラムを含んでいる。各テーブルの1つ以上のカラムは、テーブルの行を一意に識別で きる主キーとして指定され、テーブル間の相互参照には、ディスクアドレスではなく、常にこの主キーを使用し、クエリーでは、関係論理学という数学体系に基 づく一連の操作を使って、このキー関係に基づいてテーブルを結合する(このモデルが名前の由来になっている)。データを正規化されたテーブル(または関 係)の集合に分割することで、各「ファクト」が一度だけ保存されるようにし、更新操作を簡略化することを目指した。ビューと呼ばれる仮想のテーブルは、 ユーザーごとに異なる方法でデータを表示することができるが、ビューを直接更新することはできない。 コッドは、テーブル、行、列ではなく、関係、タプル、領域という数学用語を使ってモデルを定義した。現在ではおなじみの用語は、初期の実装に由来するもの である。コッドは後に、実用的な実装がモデルの基礎となる数学的な基礎から逸脱する傾向があることを批判することになる。 テーブル間の関係を表すのに、ディスクアドレスではなく、主キー(ユーザー指向の識別子)を使用したのは、主に2つの動機がありました。エンジニアリング の観点からは、高価なデータベースの再編成をすることなくテーブルの再配置やサイズ変更を可能にすることです。明示的な識別子を使用することで、きれいな 数学的定義で更新操作を定義することが容易になり、また、一階述語論理という確立した学問の観点からクエリー操作を定義することが可能になりました。テー ブル間の接続は明示的ではなくなったが、階層モデルやネットワークモデルと比較して表現力は損なわれていない。 階層モデルやネットワークモデルでは、レコードは複雑な内部構造を持つことが許されていた。例えば、ある従業員の給与の履歴は、従業員レコードの中の「繰 り返しグループ」として表されることができる。リレーショナルモデルでは、正規化の過程で、このような内部構造は、論理キーだけで結ばれた複数のテーブル で保持されるデータに取って代わられることになった。 例えば、データベースシステムの一般的な使い方として、ユーザーに関する情報、名前、ログイン情報、様々な住所や電話番号などを追跡することが挙げられ る。ナビゲーショナルアプローチでは、これらのデータはすべて1つの可変長レコードに収められます。リレーショナル方式では、データはユーザーテーブル、 アドレステーブル、電話番号テーブル(例)に正規化されます。これらのオプションのテーブルには、実際に住所や電話番号が提供された場合のみレコードが作 成される。 コッドは、ディスクアドレスではなく論理的な識別子を使って行やレコードを識別するだけでなく、アプリケーションが複数のレコードからデータを収集する方 法を変更しました。アプリケーションがリンクをたどって1レコードずつデータを収集するのではなく、どのようなデータが必要かを表現する宣言型のクエリー 言語を使用し、どのようにデータを見つけるかではなく、どのようにデータを見つけるべきかを表現するようになったのです。データへの効率的なアクセス経路 を見つけるのは、アプリケーションプログラマーではなく、データベース管理システムの責任になった。このプロセスは「クエリーの最適化」と呼ばれ、クエ リーが数学的論理で表現されることに依存していた。 コッドの論文は、バークレー校のユージン・ウォンとマイケル・ストーンブレーカーという2人の人物に取り上げられた。彼らは、すでに地理データベースプロ ジェクトに割り当てられていた資金と、コードを作成する学生プログラマーを使って、INGRESと呼ばれるプロジェクトを開始しました。1973年に始 まったINGRESは、最初のテスト製品を提供し、1979年には一般に広く使用できるようになりました。INGRESは、QUELと呼ばれるデータアク セス用の「言語」を使用するなど、多くの点でSystem Rと類似していました。時間の経過とともに、INGRESは新しい標準SQLに移行しました。 IBMはリレーショナルモデルのテスト実装であるPRTVと、製品版であるBusiness System 12を開発しましたが、いずれも現在は製造中止となっています。HoneywellはMulticsのためにMRDSを書きましたが、現在では2つの新し い実装が存在します。リレーショナルと呼ばれる他のほとんどのDBMSは、実はSQL DBMSである。 1970年、ミシガン大学はD.L. Childsの集合論的データモデルに基づくMICRO情報管理システム[13]の開発を開始した[14][15][16] MICROは米国労働省、米国環境保護局、アルバータ大学、ミシガン大学、ウェイン州立大学の研究者によって非常に大きなデータセットを管理するのに、使 用されていた。MICROはIBMのメインフレームコンピュータ上でMichigan Terminal Systemを使用して稼働していた[17]。 |
| In the 1970s and 1980s, attempts
were made to build database systems with integrated hardware and
software. The underlying philosophy was that such integration would
provide higher performance at a lower cost. Examples were IBM
System/38, the early offering of Teradata, and the Britton Lee, Inc.
database machine. Another approach to hardware support for database management was ICL's CAFS accelerator, a hardware disk controller with programmable search capabilities. In the long term, these efforts were generally unsuccessful because specialized database machines could not keep pace with the rapid development and progress of general-purpose computers. Thus most database systems nowadays are software systems running on general-purpose hardware, using general-purpose computer data storage. However, this idea is still pursued in certain applications by some companies like Netezza and Oracle (Exadata). |
1970年代から1980年代にかけて、ハードウェアとソフトウェアを
統合したデータベースシステムを構築する試みが行われた。その根底にある哲学は、このような統合によって、より高い性能をより低いコストで実現できるとい
うものであった。その例として、IBM System/38、Teradataの初期の製品、Britton Lee,
Inc.のデータベースマシンが挙げられます。 また、データベース管理をハードウェアでサポートするアプローチとして、ICLのCAFSアクセラレータという、プログラム可能な検索機能を持つハード ウェアディスクコントローラーもありました。しかし、汎用コンピュータの急速な発展と進歩にデータベース専用機が追いつけなかったため、長期的にはこれら の努力は概ね失敗に終わった。このため、現在ではほとんどのデータベースシステムが、汎用コンピュータのデータストレージを利用し、汎用ハードウェア上で 動作するソフトウェアシステムとなっている。しかし、Netezza社やOracle社(Exadata)など一部の企業では、今でもこの考え方が特定の 用途で追求されている。 |
| Late 1970s, SQL DBMS IBM started working on a prototype system loosely based on Codd's concepts as System R in the early 1970s. The first version was ready in 1974/5, and work then started on multi-table systems in which the data could be split so that all of the data for a record (some of which is optional) did not have to be stored in a single large "chunk". Subsequent multi-user versions were tested by customers in 1978 and 1979, by which time a standardized query language – SQL[citation needed] – had been added. Codd's ideas were establishing themselves as both workable and superior to CODASYL, pushing IBM to develop a true production version of System R, known as SQL/DS, and, later, Database 2 (IBM Db2). Larry Ellison's Oracle Database (or more simply, Oracle) started from a different chain, based on IBM's papers on System R. Though Oracle V1 implementations were completed in 1978, it wasn't until Oracle Version 2 when Ellison beat IBM to market in 1979.[18] Stonebraker went on to apply the lessons from INGRES to develop a new database, Postgres, which is now known as PostgreSQL. PostgreSQL is often used for global mission-critical applications (the .org and .info domain name registries use it as their primary data store, as do many large companies and financial institutions). In Sweden, Codd's paper was also read and Mimer SQL was developed in the mid-1970s at Uppsala University. In 1984, this project was consolidated into an independent enterprise. Another data model, the entity–relationship model, emerged in 1976 and gained popularity for database design as it emphasized a more familiar description than the earlier relational model. Later on, entity–relationship constructs were retrofitted as a data modeling construct for the relational model, and the difference between the two has become irrelevant.[citation needed] |
1970年代後半、SQL DBMS IBMは1970年代前半にコッドの概念を緩やかに取り入れたシステムのプロトタイプをSystem Rとして作業を開始した。最初のバージョンは1974/5に完成し、その後、レコードのすべてのデータ(一部はオプション)を単一の大きな「チャンク」に 格納する必要がないように、データを分割できるマルチテーブルシステムに関する作業が開始された。その後、1978年と1979年にマルチユーザーバー ジョンが顧客によってテストされ、その頃には標準化されたクエリー言語であるSQL[要出典]が追加されていた。コッドのアイデアはCODASYLよりも 実行可能で優れたものとして確立され、IBMはSQL/DSとして知られるシステムRの真の製品版、そして後にデータベース2(IBM Db2)を開発するよう推し進めた。 ラリー・エリソンのオラクル・データベース(またはより単純にオラクル)は、システムRに関するIBMの論文を基に、異なる連鎖から出発しました。オラク ルV1の実装は1978年に完了しましたが、エリソンが1979年にIBMを抑えて市場に出たのはオラクルV2になってからでした[18]。 Stonebrakerはその後、INGRESからの教訓を応用して新しいデータベース、Postgresを開発しました。PostgreSQLはグロー バルなミッションクリティカルなアプリケーションによく使用されています(.orgと.infoドメイン名レジストリは主要なデータストアとして使用して おり、多くの大企業や金融機関もそうしています)。 スウェーデンでは、コッドの論文も読まれ、1970年代半ばにウプサラ大学でMimer SQLが開発されました。1984年、このプロジェクトは独立した企業として統合された。 もう一つのデータモデルである実体-関係モデルは1976年に登場し、それまでの関係モデルよりも身近な記述を重視したため、データベース設計に人気を博 した。その後、エンティティ-リレーションシップの構成はリレーショナルモデルのデータモデリング構成として後付けされ、両者の違いは意味をなさなくなっ た[要出典]。 |
| 1980s, on the desktop The 1980s ushered in the age of desktop computing. The new computers empowered their users with spreadsheets like Lotus 1-2-3 and database software like dBASE. The dBASE product was lightweight and easy for any computer user to understand out of the box. C. Wayne Ratliff, the creator of dBASE, stated: "dBASE was different from programs like BASIC, C, FORTRAN, and COBOL in that a lot of the dirty work had already been done. The data manipulation is done by dBASE instead of by the user, so the user can concentrate on what he is doing, rather than having to mess with the dirty details of opening, reading, and closing files, and managing space allocation."[19] dBASE was one of the top selling software titles in the 1980s and early 1990s. 1990s, object-oriented The 1990s, along with a rise in object-oriented programming, saw a growth in how data in various databases were handled. Programmers and designers began to treat the data in their databases as objects. That is to say that if a person's data were in a database, that person's attributes, such as their address, phone number, and age, were now considered to belong to that person instead of being extraneous data. This allows for relations between data to be related to objects and their attributes and not to individual fields.[20] The term "object–relational impedance mismatch" described the inconvenience of translating between programmed objects and database tables. Object databases and object–relational databases attempt to solve this problem by providing an object-oriented language (sometimes as extensions to SQL) that programmers can use as alternative to purely relational SQL. On the programming side, libraries known as object–relational mappings (ORMs) attempt to solve the same problem. 2000s, NoSQL and NewSQL Main articles: NoSQL and NewSQL XML databases are a type of structured document-oriented database that allows querying based on XML document attributes. XML databases are mostly used in applications where the data is conveniently viewed as a collection of documents, with a structure that can vary from the very flexible to the highly rigid: examples include scientific articles, patents, tax filings, and personnel records. NoSQL databases are often very fast, do not require fixed table schemas, avoid join operations by storing denormalized data, and are designed to scale horizontally. In recent years, there has been a strong demand for massively distributed databases with high partition tolerance, but according to the CAP theorem, it is impossible for a distributed system to simultaneously provide consistency, availability, and partition tolerance guarantees. A distributed system can satisfy any two of these guarantees at the same time, but not all three. For that reason, many NoSQL databases are using what is called eventual consistency to provide both availability and partition tolerance guarantees with a reduced level of data consistency. NewSQL is a class of modern relational databases that aims to provide the same scalable performance of NoSQL systems for online transaction processing (read-write) workloads while still using SQL and maintaining the ACID guarantees of a traditional database system. |
1980年代、デスクトップで 1980年代は、デスクトップコンピューティングの時代の幕開けであった。新しいコンピュータは、Lotus 1-2-3のような表計算ソフトやdBASEのようなデータベースソフトでユーザーを強化した。dBASEの製品は軽量で、どんなコンピューターユーザー でもすぐに理解できるものでした。dBASEの生みの親であるC. Wayne Ratliffは次のように述べています。「dBASEはBASIC、C、FORTRAN、COBOLのようなプログラムとは異なり、多くの汚い仕事はす でに行われていました。データ操作はユーザが行うのではなく、dBASEが行うので、ユーザはファイルを開いたり、読んだり、閉じたり、スペースの割り当 てを管理したりといった汚いことに煩わされることなく、自分のしていることに集中できる」[19] dBASEは1980年代から1990年代初頭にかけて最も売れたソフトウェアタイトルの一つであった。 1990年代、オブジェクト指向 1990年代には、オブジェクト指向プログラミングの台頭とともに、さまざまなデータベースのデータの扱い方が拡大した。プログラマーやデザイナーは、 データベースのデータをオブジェクトとして扱うようになった。つまり、ある人のデータがデータベースに入っていた場合、その人の住所、電話番号、年齢と いった属性は、余計なデータではなく、その人に属するものと考えられるようになったのだ。これにより、データ間の関係は、個々のフィールドではなく、オブ ジェクトとその属性に関連付けられるようになった[20]。プログラムされたオブジェクトとデータベースのテーブル間の変換の不都合を「オブジェクト-リ レーショナルインピーダンスミスマッチ」という言葉で表現している。オブジェクトデータベースやオブジェクトリレーショナルデータベースは、プログラマー が純粋なリレーショナルSQLの代替として使えるオブジェクト指向言語(SQLの拡張として使われることもある)を提供することでこの問題を解決しようと するものである。プログラミング側では、オブジェクトリレーショナルマッピング(ORM)と呼ばれるライブラリーが同じ問題を解決しようと試みている。 2000年代、NoSQLとNewSQL 主な記事 NoSQLとNewSQL XMLデータベースは、構造化された文書指向データベースの一種で、XML文書の属性に基づいた問い合わせが可能である。XMLデータベースは、科学論 文、特許、税務申告書、人事記録など、非常に柔軟なものから非常に厳格なものまでさまざまな構造を持つ文書の集合体としてデータを見るのに便利なアプリ ケーションで主に使用されている。 NoSQLデータベースは、非常に高速で、固定的なテーブルスキーマを必要とせず、非正規化されたデータを格納することで結合操作を回避し、水平方向に拡 張できるように設計されていることが多い。 近年、パーティション耐性の高い大規模分散データベースが強く求められていますが、CAP定理によると、分散システムで一貫性、可用性、パーティション耐 性を同時に保証することは不可能とされています。分散システムは、このうち2つの保証を同時に満たすことはできても、3つの保証を同時に満たすことはでき ないのです。そのため、多くのNoSQLデータベースでは、データの一貫性を抑えつつ、可用性とパーティション耐性を両立させるために、最終的な一貫性と 呼ばれる方式が採用されています。 NewSQL は、最新のリレーショナルデータベースの一種で、オンライントランザクション処理(読み書き)のワークロードに対して、NoSQL システムと同じスケーラブルな性能を提供することを目的としながら、SQL を使用し、従来のデータベースシステムの ACID 保証を維持することを目的としています。 |
| https://en.wikipedia.org/wiki/Database |
|
| In telecommunications, a cutback
technique
is a destructive technique for determining certain optical fiber
transmission characteristics, such as attenuation and bandwidth. |
電気通信分野では、カットバック技術は、減衰や帯域幅など、特定の光
ファイバ伝送特性を決定するための破壊的な技術です。 |
| Procedure The measurement technique consists of: 1. performing the desired measurements on a long length of the fiber under test, 2. cutting the fiber under test at a point near the launching end, 3. repeating the measurements on the short length of fiber, and 4. subtracting the results obtained on the short length to determine the results for the residual long length. The cut should be made to retain 1 meter or more of the fiber, in order to establish equilibrium mode distribution conditions for the second measurement. In a multimode fiber, the lack of an equilibrium mode distribution could introduce errors in the measurement due to output coupling effects. In a single-mode fiber, measuring a shorter cutback fiber could result in significant transmission of cladding modes (light carried in the cladding rather than the core of the optical fiber), distorting the measurement. The errors introduced will result in conservative results (i.e., higher transmission losses and lower bandwidths) than would be realized under equilibrium conditions. |
測定手順 測定方法は以下の通りである。 1. 被測定ファイバーの長さに対して、目的の測定を行う。 2. 被測定ファイバーを発射端付近で切断する。 3. 短いファイバーで測定を繰り返す。 4. 短い方の繊維で得られた結果を差し引き、残った長い方の繊維の結果を決定する。 2回目の測定で平衡モード分布条件を確立するため、ファイバを1m以上残すように切断する必要がある。マルチモードファイバでは、平衡モード分布がない と、出力結合効果により測定に誤差が生じることがある。シングルモードファイバでは、短くカットバックしたファイバを測定すると、クラッドモード(光ファ イバのコアではなく、クラッドで運ばれる光)が大きく透過し、測定値が歪む可能性がある。このような誤差が生じると、平衡状態よりも保守的な結果(伝送損 失が大きくなり、帯域幅が狭くなる)が得られる。 |
| Cross-cutting
is an editing technique most often used in films to establish action
occurring at the same time, and often in the same place. In a
cross-cut, the camera will cut away from one action to another action,
which can suggest the simultaneity of these two actions but this is not
always the case. Cross-cutting can also be used for characters in a
film with the same goals but different ways of achieving them.[1] Suspense may be added by cross-cutting.[2] It is built through the expectations that it creates and in the hopes that it will be explained with time. Cross-cutting also forms parallels; it illustrates a narrative action that happens in several places at approximately the same time. For instance, in D. W. Griffith's A Corner in Wheat (1909), the film cross-cuts between the activities of rich businessmen and poor people waiting in line for bread. This creates a sharp dichotomy between the two actions, and encourages the viewer to compare the two shots. Often, this contrast is used for strong emotional effect, and frequently at the climax of a film. The rhythm of, or length of time between, cross-cuts can also set the rhythm of a scene.[3] Increasing the rapidity between two different actions may add tension to a scene, much in the same manner of using short, declarative sentences in a work of literature. Cross-cutting was established as a film-making technique relatively early in film history (two examples being Edwin Porter's 1903 short The Great Train Robbery and Louis J. Gasnier's 1908 short The Runaway Horse); Griffith was its most famous practitioner. The technique is showcased in his Biograph work, such as A Corner in Wheat and 1911's The Lonedale Operator.[4] His 1915 film The Birth of a Nation contains textbook examples of cross-cutting and firmly established it as a staple of film editing. Mrinal Sen has used cross-cutting effectively in his agit-prop film Interview, which achieved significant commercial success. Christopher Nolan uses cross-cutting extensively in films such as Interstellar, The Dark Knight and Inception - particularly in the latter, in which sequences depict multiple simultaneous levels of consciousness.[1] Cloud Atlas is known for its numerous cross-cuts between the film's six different stories, some lasting only a few seconds yet spanning across hundreds of years in different locations around the world. Its cuts are eased by the similar emotional tone depicted by each side's action.[citation needed] Cross-cutting is often used during phone-conversation sequences so that viewers see both characters' facial expressions in response to what is said.[5] |
クロスカットは、映画で最もよく使われる編集技法で、同じ時間、同じ場
所で起こるアクションを設定するために使われることが多い。クロスカットでは、カメラはあるアクションから別のアクションに切り替わり、この2つのアク
ションの同時性を示唆しますが、これは常にそうであるとは限らない。クロスカットは、同じ目標を持ちながらそれを達成する方法が異なる映画の登場人物にも
使われることがある[1]。 クロスカットによってサスペンスが付加されることもある[2]。それは、それが生み出す期待や、時間とともに説明されるであろうという期待によって構築さ れるものである。クロスカットはまた、平行線を形成し、ほぼ同時に複数の場所で起こる物語のアクションを説明する。例えば、D・W・グリフィスの『麦の一 角』(1909)では、金持ちの実業家とパンを求めて列に並ぶ貧しい人々の行動をクロスカットで描いている。これは、2 つの行為の間に鋭い二項対立を生み出し、見る者に 2 つのショットを比較するように促すものである。このコントラストは、しばしば映画のクライマックスで、強い感情的な効果をもたらすために使われる。クロス カットのリズムや間の時間の長さも、シーンのリズムを作ることができる[3]。2つの異なるアクションの間の速さを上げると、文学作品で短い断定的な文章 を使うのと同じように、シーンに緊張感を持たせることができる。 クロスカットは映画史の中では比較的早くから映画製作の技法として確立されており(エドウィン・ポーターの1903年の短編『The Great Train Robbery』とルイス・J・ガスニエの1908年の短編『The Runaway Horse』がその例)、グリフィスはその最も有名な実践者である。1915年の『The Birth of a Nation』では、クロスカットの教科書的な例があり、映画編集の定番として確固たる地位を築いている[4]。ムリナル・センは、商業的に大きな成功を 収めたアジテート・プロップス映画『インタビュー』でクロスカッティングを効果的に使っている。クリストファー・ノーランは『インターステラー』、『ダー クナイト』、『インセプション』などの映画でクロスカットを多用し、特に後者では複数の意識レベルを同時に描写している[1]。『クラウド アトラス』は映画の6つの物語間の多数のクロスカットで知られており、数秒しか持たないものもあるが世界中の異なる場所で数百年に渡って展開する。その カットは、各サイドのアクションによって描かれる似たような感情のトーンによって緩和されている[citation needed]。 クロスカットは電話の会話シーンでよく使われ、視聴者は言われたことに反応する両方のキャラクターの顔の表情を見ることができる[5]。 |
| Cutaway (filmmaking) Jump to navigationJump to search In film and video, a cutaway is the interruption of a continuously filmed action by inserting a view of something else.[1] It is usually followed by a cut back to the first shot. A cutaway scene is the interruption of a scene with the insertion of another scene, generally unrelated or only peripherally related to the original scene. The interruption is usually quick, and is usually, although not always, ended by a return to the original scene. The effect is of commentary to the original scene, frequently comic in nature. Usage The most common use of cutaway shots in dramatic films is to adjust the pace of the main action, to conceal the deletion of some unwanted part of the main shot, or to allow the joining of parts of two versions of that shot.[2] For example, a scene may be improved by cutting a few frames out of an actor's pause; a brief view of a listener can help conceal the break. Or the actor may fumble some of his lines in a group shot; rather than discarding a good version of the shot, the director may just have the actor repeat the lines for a new shot, and cut to that alternate view when necessary. Cutaways are also used often in older horror films in place of special effects. For example, a shot of a zombie getting its head cut off may, for instance, start with a view of an axe being swung through the air, followed by a close-up of the actor swinging it, then followed by a cut back to the now severed head. George A. Romero, creator of the Dead Series, and Tom Savini pioneered effects that removed the need for cutaways in horror films.[3][4] In news broadcasting and documentary work, the cutaway is used much as it would be in fiction. On location, there is usually just one camera to film an interview, and it is usually trained on the interviewee. Often, there is also only one microphone. After the interview, the interviewer usuallys repeat his questions while he is being filmed, with pauses that act as if the answers are listened to. These shots can be used as cutaways. Cutaways to the interviewer, called noddies, can also be used to cover cuts.[5] The cutaway does not necessarily contribute any dramatic content of its own, but is used to help the editor assemble a longer sequence.[6] For that reason, editors choose cutaways related to the main action, such as another action or object in the same location.[7] For example, if the main shot is of a man walking down an alley, possible cutaways may include a shot of a cat on a nearby dumpster or a shot of a person watching from a window overhead. |
カッタウェイ(映画製作) ナビゲーションへジャンプ検索へジャンプ 映画やビデオにおいて、カットアウェイとは、連続的に撮影されたアクションを中断し、別のものの映像を挿入することである[1]。 通常、その後に最初のショットへのカットバックが行われる。カットアウェイとは、あるシーンに別のシーンを挿入して中断することで、一般に元のシーンとは 無関係か、周辺的な関連しかない。この中断は通常すぐに行われ、常にではありませんが、元のシーンに戻ることで終了します。その効果は、元のシーンへのコ メントであり、しばしばコミカルなものとなる。 使用方法 ドラマ映画におけるカットアウェイショットの最も一般的な使用法は、メインアクションのペースを調整したり、メインショットの不要な部分の削除を隠した り、2つのバージョンのショットの一部を結合できるようにすることである[2]。例えば、俳優のポーズの数フレームをカットすることでシーンが向上するこ とがあり、リスナーの短い映像はその切れ目を隠すのに有効である。また、俳優がグループショットでセリフを言い間違えた場合、監督はそのショットの良い バージョンを捨てるのではなく、俳優に新しいショットでセリフを繰り返させ、必要に応じてその別のビューに切り替わることがある。 また、古いホラー映画では、特殊効果の代わりにカットウェイがよく使われます。例えば、ゾンビが首を切られるシーンでは、斧を振り回すシーンから始まり、 斧を振り回す役者のアップ、そして切断された首のカットと続きます。死霊シリーズの作者であるジョージ・A・ロメロとトム・サヴィーニは、ホラー映画にお けるカット割りの必要性をなくしたエフェクトのパイオニアである[3][4]。 ニュース放送やドキュメンタリーでは、カットアウェイはフィクションと同じように使われます。ロケでは、インタビューを撮影するカメラは通常1台だけで、 そのカメラは通常、インタビューされる人に向けられる。多くの場合、マイクも1本だけです。インタビューが終わると、インタビュアーは撮影されながら質問 を繰り返し、あたかもその答えを聞いているかのようなポーズをとるのが普通です。このようなショットはカットウェイとして使用することができます。また、 ノディと呼ばれるインタビュアーへのカットアウェイは、カットを隠すために使われることもある[5]。 そのため、編集者は同じ場所にある別の行動や物体など、メインの行動に関連するカットウェイを選ぶ[7]。例えば、メインショットが路地を歩く男のもので あれば、近くのゴミ箱にいる猫のショットや頭上の窓から見ている人のショットがカットウェイになる可能性がある。 |
| https://en.wikipedia.org/wiki/Cutaway_(filmmaking) |
https://www.deepl.com/ja/translator |
◎関心経済とハイパーテキスト
ハイパーテキストの概念で回る経済とは、関心経済 (Attention economy)の社会である。関心経済の定義とは、こうである。
"Attention economics is an approach to the management of information that treats human attention as a scarce commodity and applies economic theory to solve various information management problems. According to Matthew Crawford, "Attention is a resource—a person has only so much of it.""- Attention economy.
関心経済とは、人間の注意関心(=アテンション)を希少価値(→データベースへのアクセスのプライオリティが 高い)とみなし、経済理論を応用して様々な情報管理の問題を解決するた めのアプローチである。
Blue-pencil というサイトは情報管理について6つのティップスを 示している
| Need for balance of compliance and efficiency when managing
records |
記録管理におけるコンプライアンスと効率性の両立の必要性 |
| Limited awareness of when
information should be archived or disposed and lack of action |
情報のアーカイブや廃棄のタイミングについての認識が甘く、行動が伴わ
ない |
| Lack of adequate resourcing or
skill set |
適切なリソースやスキルセットの欠如 |
| Meeting information requests
while preventing violations of client confidentiality |
守秘義務違反を防ぎつつ、情報提供の要求に応える |
| Managing
exponentially multiplying information |
指
数関数的に増加する情報を管理する |
| Managing Secure disposal of all
information assets |
すべての情報資産の確実な廃棄の管理 |
そして結論である。神
は細部に宿る(Paradoxia epidemica: Der
liebe Gott lebt im Detail)、と。
◎ウィキペディアの 歴史
「ジミー・ウェールズとラリー・サンガー(=Wikipedia
の命名者はサンガー)により、ウィキペディアが初めて公開されたのは
2001年1月15日
であるが、技術的・構想的にウィキペディアの基礎となった要
素はそれ以前から存在していた。インターネット百科事典開発の試みはこれまで知られている限り、リック・ゲイツ(Rick
Gates, b.1956)による1993年のプロジェクトが端緒であったが[1]、単にフリー(無料)なのではなく、自由という意味でフリー(free-as-in-
freedom)なインターネット百科事典という構想は[2]、リ
チャード・ストールマン(Richard
Matthew Stallman, b1953)が2000年12月に初めて提唱したものだった[3]。
ストールマンの構想では、編集をコントロールする中央機関は百科事典において存在し
てはならないとしており、この点で当時の既存のデジタル百科事典(「マイクロソフト・エンカルタ」や『ブリタ
ニカ百科事典』デジタル版およびウィキペディアの前身「ヌーペディア」等)とは著しく異なっていた。1995年、ウォード・カニンガム(Howard G. "Ward"
Cunningham, b.1949)によって「ウィキ(Wiki)」
が開発されると、その技術と構想を用い、2001年にウェールズがサンガーと共に
ウィキペディアを設立した[4]。ウィキペディアは本来、インターネット
百科事典プロジェクト「ヌーペディア」を補足することを目的としていた。専門家によってのみ執筆されるヌーペディアの発展は遅々として進まず、ウィキペ
ディアが新たな記事の草案やアイディアを供給することが期待されていた。ウィキペ
ディアは発足後すぐに規模の面でヌーペディアを追い抜き、多言語にわたる
国際的なプロジェクトへと成長した。
アレクサ・インターネットによれば、ウィキペディアは2018年9月16日時点で世
界で5番目に訪問者の多いウェブサイトだった[5]。2014年の『エ
コノミスト』の記事によれば、毎日全インターネット利用者の約15パーセントがウィ
キペディアを訪問しており、月間利用者数は約4億9500万人にのぼる
とされた[6]。コムスコアの調査では、2015年におけるウィキペディアの月間ユニークユーザー数はアメリカ国内だけで1億1700万人以上に達してい
た[7]。」
◎ウィキの意 味
「ウィキ(Wiki)とは、不特定多数のユーザーが
共同してウェブブラウザから直接コンテンツを編集するウェブサイトである。一般的なウィ
キにおいては、コンテンツはマークアップ言語によって記述さ
れる
か、リッチテキストエディタによって編集される[1]。
ウィキはウィキソフトウェア(ウィキエンジンとも呼ばれる)上で動作する。ウィキソフトウェアはコンテンツ管理システムの一種であるが、サイト所有者や特
定のユーザーによってコンテンツが作られるわけではないという点において、ブログなど他のコンテンツ管理システムとは異なる。またウィキには固まったサイ
ト構造というものはなく、サイトユーザーのニーズに沿って様々にサイト構造を作り上げることが可能であり、そうした点でも他のシステムとは異なっている
[2]。
ウィキウィキはハワイ語で「速い」を意味する形容詞の wikiwiki
から来ており、ウィキのページの作成更新の迅速なことを表し、ウォード・カニンガムがホノルル国際空港内を走る "Wiki Wiki
Shuttle" からとって "WikiWikiWeb" と命名したことに始まる。」
★フロイトのマジックメモについて
| フロイト「マジック・メモについてのノート」
より 「自分の記憶に自信をもてない場合は――神経症者は驚くほど自分の記憶を信用しないが、正常な人でも自分の記憶を疑う理由はあるわけである――記憶の機能 を補い、確保するために、文書としてメモを取ることができる。このメモを保存する表面、記録ボード、あるいは白紙は、わたしの中に不可視な形で維持されて いる記憶装置のいわば物質的な部分である。このようにして固定された「記憶」が格納されている場所を覚えてさえいれば、いつでも任意にこれを「再現する」 ことができる。そしてこれが不変なまま維持され、わたしの記憶で発生する可能性のある歪曲を免れることを、確信できるのである。 わたしが自分の記憶機能を向上させるためのこの技法を十分に活用したい場合には、二つの方法がある。一つの方法は、記録したメモが不特定の長い期間にわ たって無傷のまま保存されるように、表記する表面を選ぶことである――白紙にインクで文字を書くのである。これによって「持続的な記憶痕跡」を保存するこ とができる。この方式の欠点は、表記できる表面の受け入れ能力がすぐに尽きてしまうことにある。白紙の全面に書き込んでしまうと、もはやメモを書く余地は なくなり、まだ書き込まれていない別の白紙を用意しなければならなくなる。さらに、「持続的な痕跡」を提供できるというこの方式の長所の価値が失われるこ とがある。時間がたって、メモに対する関心が失われ、もはや「記憶に保つ」ことが望ましくなくなる場合があるのである。第二の方法には、この両方の欠点が ない。たとえば石盤にチョークでなにか書くとする。この石盤は、無限の時間にわたって文字を受け入れる能力をもつ〈受け入れ表面〉となる。そして記録され た内容に関心を失ってしまった場合にも、[白紙の場合とは異なり]石盤そのものを捨てる必要はなく、メモだけを抹消することができる。この方式の欠点は、 これが持続的な痕跡を保存できないことにある。石盤の上に新しいメモを書こうとすると、その前に、すでに記録されていた内容を消去しなければならない。こ のように、われわれが記憶装置の代用として使用する道具においては、情報を無限に受け入れる能力と、持続的な痕跡の保存は、互いに排除しあう特性と考えら れる。受け入れ表面を更新するか、メモを破棄するかのどちらかなのである。 これまで、人間の感覚機能の改善または強化のために発明されてきたすべての形式の補助的な装置は、人間の感覚器官そのものか、その一部を手本として構成 されている――眼鏡、カメラ、聴診器などである。これを基準として考えると、記憶のための補助的な装置には大きな欠陥があるようである。人間の心的な装置 は、こうした補助的な装置では不可能なことを行っているからである。心的な装置は、つねに新たな知覚を無限に受け入れることができ、同時に知覚の永続的な 記憶痕跡を維持することができる(内容に変更が加えられないわけではないとしても)。すでに1900年の『夢の解釈』において、この心的な装置の異例な能 力は、二つの異なるシステム(あるいは心的な装置としての二つの異なる器官)の能力に分割できるという推測を述べておいた。一つは知覚‐意識(W-Bw) システムで、これは知覚内容を保存するが、その持続的な痕跡を保存しない。これによって、新しい知覚を受け取るたびに、まだ書かれていない白紙のようにふ るまうことができるのである。もう一つはこのシステムの下にある「記憶システム」で、これが受け入れた興奮の持続的な痕跡を保存する。その後『快感原則の 彼岸』において、知覚システムにおいて発生する意識という説明不可能な現象は、持続的な痕跡の〈代わりに〉発生するのであるという見解を付け加えた。 しばらく前から、「マジック・メモ」という名前の小さな道具が市販されている。これは白紙や石盤よりも優れた記憶保存能力を備えている道具であり、手で 操作するだけで記載内容を消去することのできる記録ボードである。しかしこの装置を詳細に検討してみると、その構成は人間の知覚装置についてわたしが考案 した構造的な仮説と、きわめて類似していることがわかる。この装置は、いつでも新たな受け入れ能力を提供すると同時に、記録したメモの持続的な痕跡を維持 するという二つの能力を備えていることを確信できるのである。」 ジークムント・フロイト『自我論集』竹田青嗣編/中山元訳、ちくま学芸 文庫、1996年、305~307ページ。 |
|
| https://note.com/hkuriwak/n/n80cd8fbc4159 |
Links
リンク
Bibliography
Other informations
Copyleft,
CC, Mitzub'ixi Quq Chi'j, 1996-2099